I made a bad joke at work recently. This isn’t necessarily unusual. The reaction to this bad joke made me think a bit more than normal though.
While reviewing some research on business models I observed that most of the models were predicated on the need to increase trust between businesses and their customers.
I wondered out loud if trust was in danger of becoming the next big over-used word and idly mused that we should get ahead of the game, joking that we should think about post-trust business models.
Unfortunately I was both believed and misheard. I was believed because sometimes I sound convincing — well, I am a middle-aged white man with a beard and a convincing poker face…—I was misheard because someone thought I said post-truth business models and, without me realising it, started researching that topic.
“Post-truth” was last year’s word of the year. It even has its own wikipedia page. The Oxford dictionary describes it as:
an adjective defined as ‘relating to or denoting circumstances in which objective facts are less influential in shaping public opinion than appeals to emotion and personal belief’.
We often talk about post-truth at the Open Data Institute. We work with data after all. People ask our opinions on it. Some people tell us that better data and more facts is the answer to the challenge of “post-truth politics”. They ask us to imagine a world where someone reading a newspaper story can click on a fact to find out who produced it. And then click on the name of the fact producer to find out who funds them. And then click on the funder of the fact producer to understand their motives. This will soon cut down on those pesky emotions and bring facts back to their position of influence.
Unfortunately, there are problems with that vision.
Why and how will people click on a fact and what will they do next? We need to make it interesting for people to want to know more, to want to dive down beneath the story into the world beneath it. We need to make sure that the world beneath the story is present and linked together. We need to give people the critical thinking skills to navigate that world.
But even that risks not being enough. If you don’t believe me ask any philosophy student. One of their early courses will be on epistomology, the study of knowledge. They might be asked whether they can prove that the chair that they are sitting on is actually a chair. The students will quickly learn that for centuries, if not millenia, philosophers have been playing around with this and similar propositions.
The student will be asked to prove that they can actually sense the world and experience the chair rather than it being a trick being played on them by a Cartesian demon, some controlling their brain in a vat, or — heaven forbid — someone about to be tortured by Roko’s basilisk for failing to bring about the AI singularity.
The students will soon realise that the concept of a chair can mean different things to different people and get taught that many languages and cultures don’t differentiate between blue and green. They will put up countless facts about chairs and a good philosophy lecturer will knock them all down. Minds get blown in epistomology courses.
At the end of a bewildering course the philosophy lecturer might ask their students to vote on whether they have managed to prove that their chair is a chair. Some hands will go up for no, some for yes, others might waver a bit. When my own epistomology course got to that point the lecturer held a vote and then started laughing. “Does it matter?”, he said, “is it a comfortable chair and does it stop your bum from hitting the ground? Yes? Then it’s a flipping chair.”
You see the world is already complex enough and humans can decide to make it even more complex by diving into all the facts to try to empirically prove everything. Some of us love to do that and there are times when it is both fun and important to lose ourselves in a sea of facts and data to see what we learn. There are great things out there waiting to be discovered.
But in our daily lives we often need to dive just deep enough. To not submerge ourselves in the full sea but instead to simply go to a reasonable level and form an idea that we can test. We can then hold that conclusion up to scrutiny. Perhaps by sharing it with a range of other people so that we can learn from their responses or by doing a simple experiment (did bum hit ground? No? Probably chair).
This can need some fearlessness, we have to be open to being wrong, but forming and testing ideas can often be a quicker path to a decent truth than all of the facts and data in the world. It might help stop some myths and falsehoods lasting for longer than they need to too.
Oh, and the person researching post-truth business models? They came up to me a few hours later to share what they’d learnt. I shamefully admitted my bad joke, profusely apologised for their wasted time and praised them for testing their ideas sooner rather than later…
In my job at the Open Data Institute I sometimes talk with people, from businesses and governments, about how better use of data can help them design and deliver better services. I’ve been using a public sector example recently that I’ve not written down. Here it is.
Ways to get bus timetable data to people who need it
The example I use is bus timetables. People need to know the times and routes of buses so they can make a journey and get to their destination. When I use the example I talk through four of the patterns that can be seen in many cities and towns around the world for services that get bus timetable data to people who need it.
Mass market private sector services: many cities and towns now have bus timetables available as open data. Private sector services like Google Maps, Apple Maps and CityMapper pick up this data and build it into a service which they aim at the mass market of smartphone users. The services work in many cities and might haveother features such as information about restaurants and pubs. They get their open bus timetable data either directly or through a data aggregator, like TransportAPI or ITOWorld, who collate data from multiple cities / transport providers. That takes aways some of the effort from using open data and makes it easier for more people to build services.
Targeted private/public sector services: smart cities and towns recognise that the mass market services don’t always meet all needs, particularly accessibility. If you look closely you can often find small bits of public services meeting the needs of some users, or a transport authority running a challenge to help focus the private sector market on meeting particular user needs. Left to its own devices the private sector might only target the profitable and easy-to-serve mass market, a challenge can help change that to build more accessible services or to experiment with new technologies like AI or voice interfaces. Targeted services often use the same data aggregators as the mass market services. It’s the same data, just presented for a different set of user needs.
3. LocalBusTimes: a local website and/or smartphone app where people can look up the timetables for a journey they want to make. It might be for a whole town or a single bus company. It probably started by only providing bus timetable data, nowadays I think more of them recommend a route. The local authority or bus company typically run the LocalBusTimes service themselves.
4. Physical services: not everyone has or uses a smartphone when they need bus timetable data. There are many reasons for this. To give just a few: there might be no coverage, they might not be able to afford a smartphone, they might have run out of credit/data, they might not want a smartphone, their city might not have made bus timetable data available or they might simply have run out of battery. That’s why bus stations have information desks, why bus stops have timetables printed and stuck to them and why people ask other people “when’s the next bus?” on the street. Someone has used the bus timetable data as part of the design for the bus stop or as part of designing an operational process to help a human answer another human’s questions.
Some of the reactions I get to my example
No one, yet…, has told me that my example is stupid or dull. Feel free to be first to do that.
When I talk through this example with people the usual reaction is that while lots of people knew about the transport sector and data few people had thought of all the patterns or wondered about how they could be applied to their work in another sector.
Most people had used the mass market services but very few people had thought of using the market, in this case through open data and challenges, to help them meet their own goals. Those that had thought that they risked losing control to the market and hadn’t realised that they could still discover if user needs were being met — for example through user research — and could use a variety of ways to shape the market to target unmet needs. Challenges are just one of the ways to do that. Governments can legislate. Both businesses and governments can use procurement, strike deals, make different types of data more open, either fully open or in a more controlled way through APIs, or lots of other forms of soft power to shape the market around them.
I also find that few people had thought of the physical services pattern as part of the overall service. I find that sad. It also shows that I’m in a bit of a bubble and exposed to only some views. The tech world is overly focussed on services that end in smartphones and websites. I expect/hope that’s a passing phase.
Why I’m writing this down now
I’m writing this down now because I’ve been using the example for a while. It’s good to publish it to get my thinking straight, to show some of the reactions I get and to learn from new reactions. As I often say, data is becoming infrastructure that will be as open as possible. Businesses and governemnts need to adapt to that future. They have different goals, and needs for democratic accountability, but can learn from and collaborate with each other. I’m expecting to do some more work on public sector service delivery models over the next few months. It’s good to share, even shoddy, thinking early. It’ll help make that work better.
Warning: this post contains content that will be offensive to some people.
The post is a version of talk I gave at the ODIFridays series of lectures at the HQ of the Open Data Institute in London. The slides and a video of the talk are at the end of the post. Like most of my talks I adlibbed a bit. The post has links to most of the material I adlibbed from, others are at the end of the slides. It includes some thoughts on swearwords, Roger Mellie, democracy, censorship, Blackpool FC, artificial intelligence, context and an apology to my mum.
One of the UK’s regulators, Ofcom, commissioned research on offensive language last year. The research got lots of headlines. It was a nice opportunity for papers and websites to make cheap gags about swear words.
But it also gave me an opportunity to open up some swear word data and to use that example to talk with people and think about things like democracy, censorship, context and artificial intelligence. I made some cheap gags about swear words too.
After some discussion within the ODI and with Ofcom’s research team we ended up with this. The same data as the PDF but in a format that is both human and machine readable.
Now, a big part of our job at the Open Data Institute is “getting data to people who need it”. Normally I start with problems but this time I had started with data. My bad. Now to find out who needed it and how they would use it.
Some of the things people use this swear word data for
As I put the data out on twitter there was a background mantra of “arse…balls….knob…bastard…” from around the office. One person then wrote a little script that people could use to get their computers to say the list of words. Soon I could hear both human and machine voices swearing away. The swearing mantra was charming, if a little unsettling, but I had my serious face on. Why do people swear?
The main purpose of swearing is to express emotions, especially anger and frustration.
Seems fair. I suspect that a lot of people get frustrated at not being able to get data they need to do something. That explained the background mantra from the Open Data Institute office, but what about other uses of the data?
Roger Mellie, copyright Viz. Note that the swear word data might allow people to block his language, but not his gestures.
The content of the report told us about some other users. It would help TV broadcasters and presenters understand how people would react to things that they said on air and so help the presenters decide what they could say.
For example the word “bollocks” was seen as somewhat vulgar if it referred to testicles but less problematic if it was being used to call something ‘nonsense’.
This might mean that people did or did not say words in certain contexts. It might lead to some content only being accessible if a PIN was entered to unlock it.
We have given Ofcom the power to fine organisations and people that breach their codes. By publishing the report openly, they were helping broadcasters understand how they might use those powers and therefore discouraging breaches. This probably makes the system cheaper and more effective.
Broadcasters are likely to have their own guidance to help them meet the expectations of their target audiences. They could merge Ofcom’s list with their own list to help them meet both society’s needs and their own user’s needs.
Similar data is maintained in contexts outside of TV and radio
In Britain Mary Whitehouse was a famous campaigner from the 1960s to the 1980s against things that she found offensive. I can imagine Mary being keen on data-driven censorship. Image fair use via Wikipedia.
The data includes the word ginger saying it is ‘mild language, generally of little concern’, but the word ginger can also be used to describe a very tasty type of biscuit. A filter that used the swear word data to block offensive words might ban ginger nuts. That would be bad. This is a common problem with simple data-driven solutions. They ignore context.
I couldn’t find a list of offensive biscuit names but there are other sets that are similar to the swear word data used in contexts other than TV and radio.
The UK has a list of suppressed car registration plates
It is the job of part of the UK government, the DVLA, to maintain a list of combinations of letters and numbers that you cannot put on a car. Unfortunately, and curiously, the list is not published openly, but sometimes it is made available after freedom of information requests.
An extract from the suppressed car registration plate list via Whatdotheyknow
The list of suppressed car registration plates helps prevent confusion over typographically similar symbols, like o (zero) and 0 (oh). It blocks language that is likely to be considered offensive, for example “*B** UMS” and “*R**APE**”.
The list also explicitly contains the names of terrorist groups such as the UVF, UDA and UFF. Another terrorist organisation, the IRA, are already banned, like any other organisation beginning with I, because of the potential for confusion between 1 (one) and I (aye).
More controversially the acronym for the far-right British National Party, BNP, is also on the list. The BNP are allowed to stand in the UK’s democratic election process. How was that decision made? Unfortunately just as the list isn’t publicly available neither is the methodology.
Context affects what words are offensive
The UK’s democratic processes produce others lists of offensive words.
The speaker in the UK’s parliament can request that politicians withdraw words when debating with their opponents, so called unparliamentary language. The way in which words are deemed to be unparliamentary or not are unclear. In 2015 the opposition leader Ed Milliband was allowed to call the then Prime Minister David Cameron “dodgy”, yet in 2016 an opposition backbencher Dennis Skinner was asked to leave a debate because he called David Cameron “dodgy Dave”. The word “dodgy” isn’t on Ofcom’s list, it’s offensive to call an MP “dodgy” in a parliamentary debate but not to call them it on television.
The word “Oyston” is offensive to me and my community of fans of Blackpool football club. The offensiveness is not only because of this cringeworthy picture but because of how the Oyston family treats fans.
Another example of offensive language in a particular context is the word “Oyston”.
The Oyston family own the football club that I support, Blackpool FC. Because of their actions against fans being called an Oyston fan on one of the websites used by Blackpool fans would be offensive. How would anyone outside of the community of Blackpool fans discover this?
There are related examples that may help us understand how we could do this.
Collaborative maintenance of data
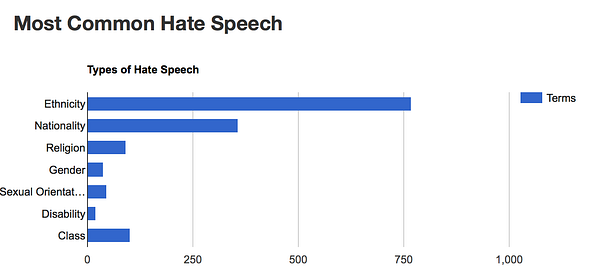
Hatebase maintains a list of hate speech from around the world. The data is maintained by automated processes and manual interaction to cater for how hate speech changes over time and in different places. Hate speech can be used to encourage violence against people and communities. The collaborative maintenance process allows people to debate which words are hate speech or not.
Other people could learn from the example of Hatebase. If British politicians wanted, and could get to grips with github, then they could collaboratively maintain my initial list of unparliamentary language and create something that would help them understand the boundaries of offensiveness.
Offensiveness is affected by time, place and communities
By this point in my own research I was clear that the context of offensiveness is affected by time, place and communities.
When I checked I found that swearing philosophers were, of course, already aware of this. As often happens I was a technologist rediscovering ground that others had already covered. But technology can also affect how and which words become offensive.
People create new offensive words
Oyston is an example of a word that became offensive to a small group of people before becoming offensive to a larger group. Blackpool fans have effectively used social media and the press — oh, and talks & blogposts like this ;) — as part of a campaign to get the Oyston family out of our football club. An effect of this has been to spread the understanding of the offensiveness of the Oystons from the seaside to wider parts of the footballing community. A more famous example is the case of Rick Santorum who found his surname defined as an offensive word in a campaign led by Dan Savage.
This is a challenge to any list of swear words and a risk for people who use them. People create new offensive words for their own purposes. They game systems.
Would people game the swear word data I created from Ofcom’s list? Yes, of course they would.
An example quickly came to mind. When I published the Ofcom offensive word list as open data then in line with good practice I gave every entry a universally unique identifier (UUID). UUIDs make it easier for machines to use the data.
If this data was to get widely used then how long would it be before people started to circumvent the system by being interviewed on telly wearing t-shirts with the UUID of a swear word? Perhaps over time the UUIDs, or parts of them, would become offensive? “That fella’s a right 81cb.“, they’d say. Maybe the UUIDs would need to be added to the list as they became offensive?
People adapt and change. That is one of the best things about people and one of the biggest challenges we face when maintaining and using data. We need to build in mechanisms to change datasets over time as needs and uses change.
Swear words-as-a-service is hard
It is clear that swear word data was easy to build and also clear that it would be more difficult to maintain and make it useful in multiple contexts.
I knew that many companies were already maintaining similar lists as, like many other people, I had seen, laughed and evaded filters on websites that had turned the British town of Scunthorpe into the apparently inoffensive “S***horpe” due to simplistic and bad data-driven algorithms. I do wonder how useful those filters and services are.
Many of the website filters I had seen are simple and flawed because of the lack of context and their inability to adapt to people’s changing behaviour but thinking ahead I wondered if people would start to apply machine learning / artificial intelligence (ML/AI) and create services that could automatically learn new swear words? Perhaps this could be used on a massive scale to reduce the damage caused by offensive language on the web?
I knew that I wouldn’t be the first person to think of this idea. While 2016 had been the year when every problem could be fixed with a blockchain, 2017 is the year of ML/AI.
A quick search of patent libraries showed that in 2015 Google had registered a patent to classify offensive words using machine learning. Unfortunately it looks rubbish. The training mechanism worked on a large set of text samples, it failed to recognise the context in which the text was being used. The resulting service might be slightly better than current filters but would still be data-driven rather than informed by data.
Maybe, like Hatebase, it would help if users were to train the machines that provided the service. After all Google, like most other large internet companies, use thousands of people — including you — to help train their services. I started to consider what I had learn about offensive language and think of the tasks that Google would need to give to swear word raters to train their machine:
Task: go to a football ground in Gdansk, Poland. Play this video to people near you. Observe their attitude to you, and each other, over the following seven days and then categorise the offensiveness of the video. Repeat this exercise every 3 months.
Hmm… I quickly realised that this might be a Quixotic mission and that AI/ML might provide a better service but still only a partial one. There would be no perfect service. People decide what is offensive, not machines. If the service only considered some contexts then the people who controlled the machines and trained them on those contexts would be the ones who decided where it was useful. Swear word data isn’t like the location of bus stops or the list of transactions in a bank account. The context is even more important.
This is one of the challenges of the web and providing data and services for it. The web is pervasive. It interacts with the physical world in many places. It appears in multiple contexts. I use the web to watch broadcast news, like that regulated by Ofcom. I use it keep up to date on politics, where the unparliamentary rules are useful. I talk about football, and the Oystons, on message boards. I keep up to date on current affairs, and feel helpless at the levels of hate speech deployed at people in the UK and abroad. I chat to friends, both publicly on sites like Twitter and Facebook and also privately in messaging applications.
Datasets and services that reduce offensive content on the web will need to cater for all of these different contexts, and more. Even if they do, some people will still work around them. Data and technology may be able to help the problem but it will only ever be part of a solution to something that is fundamentally a more human problem. Our need to express our emotions in language.
Sorry mum
It was clear from my investigations that we could usefully create data about swear words, i.e. words that are offensive. That the need for this data came from people who swear, people who didn’t want to swear and societies & communities trying to decide the boundaries between what was offensive or not. That it would be useful if the research and rules for deciding on what was offensive were open. And that if people could collaborate to decide on what was offensive that the data would be more useful because it would cater for more contexts. But it was also clear that while technology creates new possibilities to reduce offensiveness that people will still adapt to achieve the goal they want. So it goes.
The other thing that was clear from the talk was mine and my audience’s squeamishness with some of the words. In my case it was certainly because of one of my most important contexts: my upbringing and my family. I’d like to end this post the same way I ended the talk by apologising to my mum. Sorry mum.
The questions from the audience showed the importance of context
At the end of the talk at the ODI the audience raised several points about offensive language that had not been covered in the talk, such as the use of racial and religious slurs. I was already covering a wide topic. Racial and religious offensiveness cover even more ground. I couldn’t cover everything.
Image from The Wanderers, based on a book by Richard Price. The film includes a fantastic scene in a 1960s New York school where people of different religions and ethnicity try, and fail, to remember all of the offensive names they have for each other.
I did find it interesting that the audience in the room hadn’t heard of some of the words in the list. Particularly choc ice, blood claat and bum claat, words that in my — white, middle class, mostly Northern England and South London experience — are used against black people or in black communities. In the case of the latter two more specifically within Jamaican communities.
That people hadn’t heard of these words says something about the context of the audience. A context where those words may not have been seen as offensive. Perhaps next time I talk on this topic I should try and sneak in some offensive language from different contexts to see what happens.
Watch the original talk or read the slides
If you want you can watch a recording of the talk (which includes some swear-a-long fun):
Hello. This is the personal website of Peter K Wells. I do politics, policy and delivery to try to make data and technology benefit everyone. I also do bad jokes and music references.
This website stores cookies on your computer. These cookies are used to provide a more personalized experience and to track your whereabouts around our website in compliance with the European General Data Protection Regulation. If you decide to to opt-out of any future tracking, a cookie will be setup in your browser to remember this choice for one year.