A picture of some people by L S Lowry (via Flickr)
The committee is currently investigating Artificial Intelligence and whether the existing frameworks and regulations are sufficient to ensure that high standards of conduct are upheld as technologically assisted decision-making is adopted more widely across the public sector.
Big topic. After all AI is a range of techniques that uses people, mathematics, software and data to make guesses at the answer to things. It can help, and hinder, with lots of the huge array of things that the public sector does.
I represented the Open Data Institute (ODI) on a roundtable for this investigation. A couple of people have asked me what the roundtable was like and what I said. Here’s a quick blogpost.
Preparing for a roundtable
The ODI team get invited to lots of roundtables and events. We decide which ones to do and who does them based on a range of criteria. The invitation for this one went to our CEO, Jeni Tennison, she passed it to me to do. My goal was to help the committee, learn from what other attendees were saying, and test some of our ideas in front of this audience.
We did our usual preparation by sharing the questions around the team in the office and telling our network that we were going along to hear what advice they gave us. That technique provides a lot of input. It also helps me represent the ODI and the ODI’s network, rather than simply myself and my own views.
I summarised it down to a few key points to try and make, and then tried not to over-prepare. Over-preparation is the worst sin: it makes me sound even duller than normal.
Rounding a table
The roundtable itself was at Imperial College in London.
The setup was more informal and the committee was more friendly and asked more insightful questions than most similar things I’ve done. That was good. My background is technical and private sector — I previously spent 20 years working with telecoms operators building products, systems and networks — so I always worry that I’ll misunderstand or miscommunicate particular words or phrases. That would damage both me and the organisation I represent.
Anyway, I managed to get over versions of some of things that we’d prepared and/or that we regularly discuss in the office and that were relevant to how the roundtable took shape:
that there is little transparency over use of AI in the public sector and of how the UK government’s Data Ethics Framework is being used. I know that there is good and bad work being done, but mostly because I know some of the people doing it. How are the general public meant to know?
that we need to focus more on the people who design, build and buy AI services. Exploring what responsibility and accountability they should have and how we give them the space, time and money to design those services so that they support democracy, openness, transparency and accountability as well as being efficient and easy to use
that the current focus on ethical principles and AI principles do not seem to be having a usefuleffect. That instead we need to couple those top-down interventions with more bottom-up practical tools (like the framework or ODI’s Data Ethics Canvas) and more research into how the people designing, building or buying AI systems make decisions and what will influence them to comply with the law and think about the ethical implications of their actions
that control, distribution of benefits and harms, rights and responsibilities about AI models would be a useful area to explore
that eliminating bias is the wrong goal. Bias exists in our society, some of that bias becomes encoded in data and technology. AI relies on the past to predict the future, but the past might not reflect the present let alone the world we want. We should build systems that take us towards the future we want, and that can adapt as things change
I also learnt a lot from other attendees with some interesting things for myself and the team back in the office to chew over.
After the roundtable
A couple of weeks after the roundtable I was sent the transcript to review. The committee will publish that transcript openly — which is good and healthy. Attendees get to see the transcript first so they can suggest corrections to simple grammatical errors or transcription problems. That’s why I’m not commenting on or sharing what other people said.
It is important to review the transcript. There are sometimes errors. For example, in this transcript I was recorded as saying that my boss, Jeni, was “whiter than me” rather than “wiser than me”. I have no idea how I’d measure the former but I certainly know that she’s the latter. Some of the words and thoughts in this blogpost come from Jeni and others in the team like Olivier, Miranda, Renate, Jack &c &c &c.
Reading the transcript also helps me understand the difference between the clarity of my speech and the clarity of my writing. I’ve left most of my spoken errors in place. Just like the state we can’t only communicate in words and pictures that are sent through a computer. Most of us need to get better at speaking with humans.
At the Open Data Institute we use a theory of change. It is one of the tools that we use internally to help us make decisions and externally to explain to people what we do and how we do it.
Our theory of change describes the farmland, oilfield and wasteland futures and helps us try to steer between the extremes of the oilfield and wasteland futures to get to the farmland.
The wasteland future emerges when there are unaddressed fears arising from legitimate concerns — such as who has access to data and how it might be used.
We frequently talk through the theory of change to explain what we do and how we do it. We try to provide pauses in the conversation to get other people to give their opinions. It helps people to think and learn for themselves. It helps us learn too. We hear what other people think happens in the wasteland future. How they think people and organisations will react to their fears being unaddressed.
Most of us the people we talk with think that the wasteland future has a lack of data. They realise that with a lack of trust then many people and organisations will reduce how much data they share. They imagine people refusing to use services because they don’t trust them, and that organisations similarly refuse to share data because they fear being punished. They think the data stops flowing.
These tips—based on insurers using social media data to set premiums—are stunningly dystopian. pic.twitter.com/uceFFIThyO
A smaller group of people realise the wasteland is more complex and weird. People’s behaviour will change in many different ways. Humans are fun like that.
Some people might post inaccurate data. Perhaps you will post fake claims of jogging exploits to social media if it is the only way to get a fair life insurance deal. Other people will hide in the data. Maybe we will give our children common names so they are hard to identify or so they appear to be from an ethnic group that is not discriminated against.
I’m sure that even if you hadn’t thought of them at first you can now think of many more things that happen in the wasteland future.
You can see some of this future now. There are already people and organiastion hiding in the flows of data. Some of those people need and deserve help to hide because they have a genuine fear of harm, perhaps due to their political beliefs, ethnicity or sexuality. Equally there are others who are trying to evade fair scrutiny, for example tax dodgers and other criminals, and organisations providing services to help them do so. But if we increasingly fear harm then more people will want and need these services and, inevitably, they will become ever cheaper and used by more of us.
As this behaviour becomes widespread we will see data that is massively biased and misleading. People and organisations that use data-enabled services to tackle global challenges such as global warming, to price a life insurance premium in a way that doesn’t unfairly discriminate, or to decide whether or not to take a job will struggle. That would not be good for any of us.
Navigating the a route between the wasteland future and a different future where we get more economic and social value from data will not be easy. There will always be some people who need to pollute and hide in data to protect themselves from harm, we need to allow that to happen. Understanding and addressing people’s fears is not only a technical challenge, it is also a social and political one. To retain trust we need businesses and governments to adapt to people’s ever-changing expectations in a range of cultural contexts.
An increasing fear of how data is used will not simply stop people using services or sharing data, it will change peoples behaviour in a range of ways. If that happens we can expect data to be increasingly poor quality, biased and misleading. And that pollution will make data less useful to help people, communities and organisations make decisions that hold the potential to improve all of our lives. Some of that potential is false — the use of data required is too scary and people do not want or need it — but that is why it is important to understand and address the concerns we can if societies are to navigate towards the farmland.
Seven patient months later a company called vSport are reported to have bid for Blackpool FC and are quoted saying that they expect to complete the purchase by the end of the month.
Sounds impressively futuristic but what on earth does that mean? And should fans and journalists be welcoming the news, or undertaking a bit more scrutiny?
What on earth is blockchain?
Blockchain is a new technology that is generating a lot of interest. Many people believe that it will change the world.
I was part of a team that looked at blockchain two years ago. Our first assessment was that it was useful, but not for everything. We then wrote a longer report, which looked at the promises and risks. Our simplest definition was:
Blockchains provide a way to store information so that many people can see it, keep a copy of it, and add to it. Once added, it is very difficult to remove information. This can reinforce trust in a blockchain’s content.
This type of data storage can support lots of new business and organisational models. Bitcoin is the most famous new model associated with blockchain, indeed blockchain was invented as part of the development of Bitcoin.
I still haven’t seen one working at scale. And I do spend time looking, Because while I still think there may be some good in blockchain (making it really hard to change data, and making it easier for more people to see when it is changed, must be useful for something! perhaps our project on national archives will help find it?) there is also a lot of hype.
It is good to see that the hype is gradually being seen by more people. We need to get past it to see where, or if, blockchain can be used for positive purposes. Where there is hype there is danger. Not just of lost money — some people will always lose some money while experimenting with new technology — but of more unintended harmful impacts, such as Bitcoin’s impact on the environment, or a direct and immediate impact on individuals.
As societies we need to experiment with new technology to see where it could be useful, but we need be wary of harmful impacts and who could be affected. In the age of a global internet and world wide web, harm can happen at great scale and speed.
The two previously founded a company called Sport8. The English-language version of Sport8’s website has not been updated since 2015 although the Chinese-language version seems to have been more recently updated.
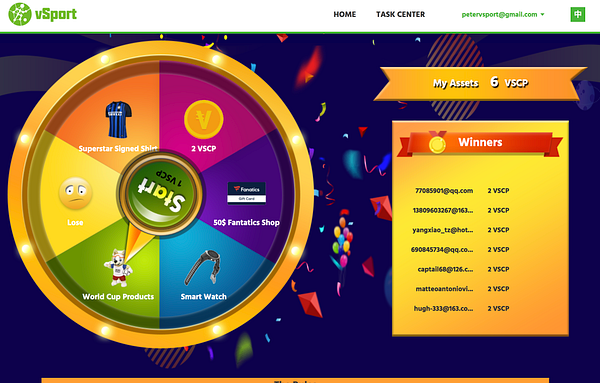
vSport, like many other companies, has raised some initial funds from investors, put out some blogposts and a whitepaper and is trying to show its potential so that it can bring in more funds. When I signed up on the website I got the chance to play a boring roulette game, I don’t think that game will bring in many funds or players in Blackpool.
The whitepaper has lots of big words and claims but little technical information or detail on how the capabilities will be built and adopted across the many claimed scenarios. I couldn’t find any source code to review, either to check if the roulette game was fair or to help form an opinion on whether the larger technical claims were credible.
The list of applications on the website and in the whitepaper is long and varied. In the time it would take to build a business across the sports sector then most of these ideas would be out of date. If I was advising them then, as for most other blockchain companies, I would recommend that a little more focus and a lot less hype would make them more likely to have long-term success.
from the vSport whitepaper
Some of the applications are a little strange and will have harmful impacts. For example, a section on data sharing talks about personal data like people’s names, sports activities and achievements being put into the blockchain. It says that this could be used in marketing and in making decisions about teenagers at school. Don’t put personal data in a blockchain. Sometimes people need protecting and data about them needs changing or removing. The very same factors that make it hard to change data in a blockchain, also make it hard to protect the people that the data is about.
Most of the applications don’t require a blockchain, they could be built with existing and less experimental technologies, and most of them are about creating financial value for vSport, football clubs, and celebrities but, one of the promises of blockchain is that it can widen the number of people involved in decision making.
from the vSport whitepaper
If vSport follow that model (and the whitepaper hints at this) then football fans could influence its direction and get it to build applications that they want. Perhaps Blackpool fans could vote to finally build a training ground?
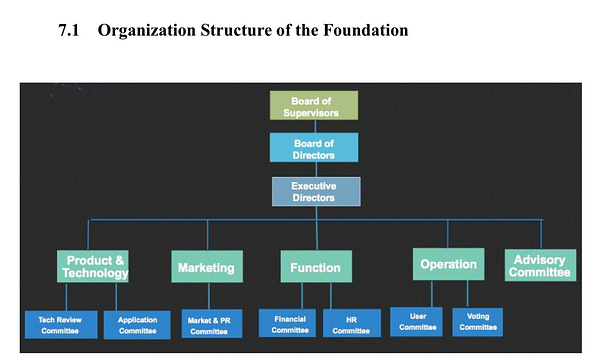
Unfortunately the limited information about the foundation shows a simple organisation chart with no detail of who is in which box, how decisions are made, and how they can be appealed.
vSport looks like the very early stage of a classic top-down business. Lots of promises, few products and in need of customers to both develop the products and prove that it can deliver what it promises. I worry that it wants to buy Blackpool football club either for marketing or to test its new technology on the club and fans.
vSport needs more scrutiny
Blackpool fans have had a terrible time. Many, like me, haven’t been to see their football club in years. Any escape route from the Oystons might seem a good one but vSport doesn’t seem the right next destination.
Being either a marketing vehicle for vSport or a testing ground for its technology doesn’t seem like something Blackpool FC, its fans, or its community need. Fans, journalists and local councillors (who’ve hopefully learnt a lesson from their failure to get to grips with the Oystons) need to ask more and better questions of any potential new investor. Any investor that fails to talk with fans before bidding should immediately raise alarm bells.
Many fans were happy to start a new fan-owned club if the Oystons failed to leave. We can ask more questions of vSport, or wait and see if Belokon can use his court case to get ownership from the Oystons, but we should also continue to be prepared to start a new club rather than accepting the first rescue ship that comes along.
I moved to Newcastle in the North East of England last year. It’s a great place, but one of the things that first struck me about the town was the roads. There’s a motorway right through the town centre. It makes me think of tech and data, and the need to broaden the debate.
Roads for prosperity
Aerial view of the construction of the Central Motorway and Swan House roundabout, estimated to be in 1971. Image via The Evening Chronicle
When we were looking for a place to live we stopped in a few hotels near the town centre. They were on both sides of the motorway.
One side is full of shops, restaurants, cinemas, theatres and bars. The other is full of newly built university accomodation. There’s some rather strange, and a bit scary when it’s late and you’re tipsy…, skywalks connecting the two.
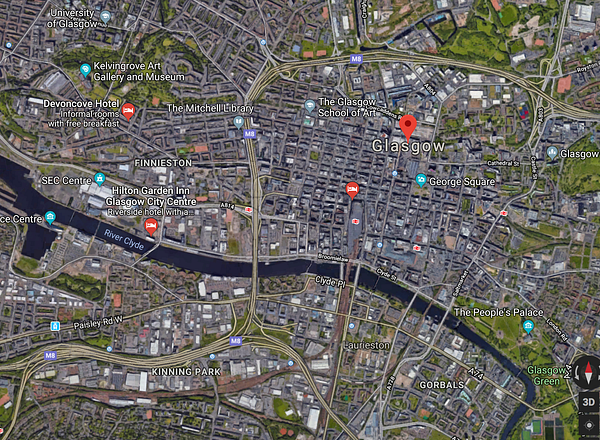
Glasgow motorways, courtesy of Google Maps and their various data suppliers
It was built following the Traffic in Towns report by Professor Sir Colin Douglas Buchanan. The report focussed on the growth in road traffic by cars, and the potential economic benefits that could be gained by supporting it.
Traffic in Towns was later followed by a 1989 government white paper, called The Roads for Prosperity, that followed the same tracks. Both reports gave a higher emphasis to inreasing road use and cars than to reducing environmental impact or other transport options, such as mass public transit or walking. They were design standards for urban transport. Their priority was economic growth.
Urban planners in other UK cities, like Birmingham and Glasgow, followed the same reports and the standards they set. Existing communities were again displaced or affected by roads that were built. A similar story happened in countries and cities across the world. Sometimes earlier, sometimes later.
New York City in the 1920s, Beijing in the 2000s
From the 1920s Robert Moses rebuilt New York City to favour car users as part of larger urban transformation plans. He constructed highways, bridges and parkways that cut through the city and surrounding regions to get cars to where they wanted to be. Debate over the impact of these decisions on communities, and whether Robert Moses’ politics and racism played a part in his decisions and the type of road uses he favoured, continues to this day.
Robert Moses had set the standard, other people followed his lead. Urban planners across the USA built roads that favoured road users and impacted on existing communities living in or near their path.
I was there in 2003 and remember standing in a hutong neighbourhood due for demolition. A resident showed me the straight lines on the map indicating where new roads were being built, and the lanes, streets and houses underneath that were either being demolished or left with greater air and noise population.
The potential benefits to be gained from the new roads had been decided to be greater than the current needs of the people who lived in Beijing. This wasn’t just about the Olympics. As part of the transition from the communist system under Mao Zedong to the market socialist / state capitalist society of current China there were similar infrastructure changes happening elsewhere across the country.
People push back
In each of these cases central authorities had decided that the potential economic gains outweighed the negative impact on people and communities without involving them in the process. People protested at the time but over the years the push back became more effective. It ended up changing the way we plan.
Anyone who followed the environmental protests in the UK in the 1990s will remember Swampy. (image copyright Reuters, I think).
In the UK there were growing protests against road developments during the 1980s and 1990s with calls for integrated transport solutions that considered different types of users like car, bus, rail, freight, bicycles and pedestrians and a reduced impact on the environment.
Gradually UK urban and road planning guidelines were changed to include the need for public consultation and the consideration of societal impacts like air quality, noise or other environmental issues. We now consider more viewpoints and needs before a decision is a made.
In parts of the USA change happened earlier. Jane Jacobs was one of the most famous figures amongst the groups in New York City arguing against Robert Moses’ plan to redevelop Greenwich Village in the 1950s and 1960s. She was part of the Joint Committee to Stop the Lower Manhattan Expressway, the ‘slum’ clearances it proposed and the decrease in air quality that it was forecast to generate. The Committee eventually won. Jane Jacobs started to formalise her thinking on urban planning in the book The Death and Life of Great American Cities. It argued for a new standard for urban design which shifted the emphasis towards the people who lived in the city.
I believe data, and large parts of what we call the technology or digital sector, are becoming infrastructure, just like roads became infrastructure in the past. This means that we need to think strategically and for the long-term. The effects of the decisions that we make today will persist.
One of the things I’ve been doing over the last few years is reading about the history of technology-driven change. Things like the wireless, telephone, radio and roads. The web and internet have helped us communicate over a larger scale and at much faster speeds than previously, but we are still humans. We can learn from our history and the stages technology goes through as, or if…, it gets adopted. Perhaps by learning more historical lessons we can go through those stages faster and make better decisions than before.
An important of this process is how we moved from infrastructure decisions made solely by technocrats, whether in companies or in governments, to decisions being made with society and through our democratic processes. Unfortunately technology and data is currently stuck in the world of the technocrats with very little public involvement. We have more progress to make, otherwise the protests and bumps on the roads will get bigger.
We need to broaden the conversation, and open things up
We need to have broader conversations about technology.
This will be particularly important with data. Most data is about people, and multiple people at that. Our DNA reveals information about our parents, family and even our distant relatives. Utility bills reveal who we live with. Health records contain information about medical professionals as well as ourselves. Data is about us, our families, communities and society.
When we learn how to design services for multiple people then we will have to think about their different interests and rights & how they might compete with each other.
Yet, most internet services, and much current data regulation, are designed for individuals, particularly those who are currently online. That’s part of why technology can feel uncomfortable for many. It doesn’t match much of our societies. Rather than reflecting the richness and variety of communities and societies around the world tech is bringing in the political beliefs and cultural values of the people who built it.
As the French government showed with the Digital Republic Bill, and UK organisations like DotEveryone and the Carnegie Trust are exploring, engaging the public in decisions about technology is complicated but possible. We need more politicians and large technology companies around the world to embrace this approach.
We need to have broader and more open conversations that allow the public to both take part in and influence the outcomes of the current debates about technology. We need to go beyond technology experts to include a range of other experts and the people, businesses and communities who could be beneficially or negatively impacted by a decision. They will have different opinions, and different societies will choose to give those opinions different weights, but learning from the range of views and how they develop during a debate will help us make better decisions.
As societies learnt when we were building roads the debate can’t be left to technocrats solely focussed on economic gains, it needs to be opened up to the public so that we can also debate societal values.
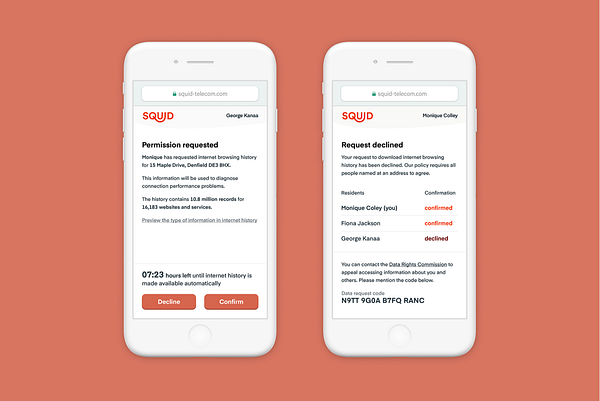
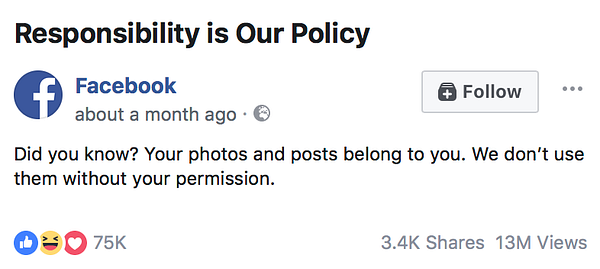
It told me that my “photos and posts” belong to me and that “[Facebook] won’t use them without [my] permission”.
The same advert has appeared in the feed of friends and work colleagues based in the UK. It seems to be part of a campaign. Perhaps the campaign is related to the imminent European Union’s General Data Protection Regulation and the growing public awareness that there is debate around data, how it is used, and whether to trust those uses.
“You own all of the content and information you post on Facebook, and you can control how it is shared through your privacy and application settings”.
Both messages are simplistic, at best. I don’t fully own or control the content I post on Facebook. It doesn’t only belong to or affect me. By over-simplifying its messaging Facebook, like many other organisations, is missing the chance to help explain how its services work and help us all make better decisions when sharing content.
Social media content is more complex than you might think
This will sound counter-intuitive to many. I mean shouldn’t I have control over my data on Facebook? It’s about me! I created it!!
These people are not my friends. They are from a film called Peter’s Friends. But it shows some people in a picture they may regret in later life.
My list of friends is a list of relationships with other people, people tag someone in a post saying that they went to a restaurant or pub with them, or share a picture or comment about a group of friends.
Most of us will think about our friend’s feelings when sharing content about them on social media, but we don’t always know what will be important to them. The rules aren’t written down. Many of us will have had the experience of sharing something and then having a friend say “hi, do you mind deleting that post because of X…”.
Sometimes we listen to those objections and sometimes we don’t. Our friends might not be able to delete our Facebook content without our consent but their views are part of the complex set of things we think about when posting. They can unfriend us in real-life as well as on social media.
Adverse impact on other people
Beyond affecting a personal relationship there are many types of adverse impact that a Facebook post might have. Affecting copyright owners is one. Copyright has manymanyflaws but it is one of the ways societies help creators benefit from their work.
If I did own all the content I posted on Facebook then presumably I could post a picture created by someone else and start to make money off it by selling things. Money that could have gone to the artist.
I could, but I shouldn’t.
Both Facebook and I recognise that we need to abide by copyright legislation and that governments help enforce it. A copyright holder can complain directly to Facebook, or through the relevant national or international rules. The content is not mine to own to control and use how I wish. If I breach copyright in a way that unfairly impacts creators then fewer nice things get created. That would be bad.
Germany recently passed a new law stating that social media platforms have to take down hate speech within 1–7 days or face large fines.
Going deeper into adverse impact it could be that someone on Facebook posts something with the intent of causing harm.
Facebook is a global service, and the legislation and definitions of those things will change from country to country, but in many countries those things would be illegal. A poster would lose control of the content, and perhaps even their liberty, as democratic governments use the powers given to them by people to stop the content from being seen and shared.
Facebook has its own moderation rules and tools that allow Facebook’s moderators to intervene proactively or for people to report content and get it removed. Again, that removal can happen without the poster’s consent. The poster is not in control.
Not all of the adverse impacts that moderation rules try to prevent are illegal and intentional. Others are unethical, or against social norms for a particular community or society. Moderation exists because the adverse impact from my posts might damage the health and goals of a community.
Moderation is not only done by Facebook and governments. Many community groups within Facebook have their own moderators and policies. Group moderators can also remove content without a poster’s consent.
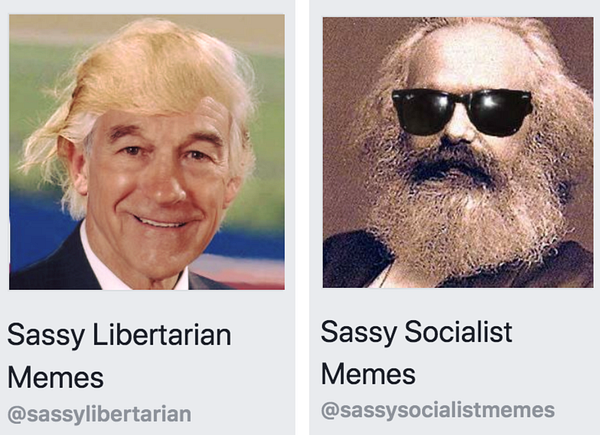
Perhaps the moderators of sassy socialist memes or sassy libertarian memes will remove content I post in their groups if my content just ain’t sassy enough. The local Facebook group for the town I live in, like many other local Facebook groups, certainly has a fierce response to excessive advertising or outsiders criticising the town.
Other people can benefit from content
Shifting to a more positive, and less sassy, note people should also be aware of other people who can benefit from content they post. As the Financial Times recently noted “an explosion of [trustworthy data, such as that posted on Facebook] would give us the capability to understand our world in far more detail than ever before”. Facebook shares some of the data you post already so that other people can benefit, I think it should do more.
OpenStreetMap’s data is freely available as open data and used by governments, businesses, communities and indivudals all over the world.
For example, Facebook users help maintain data about things like cafes, restaurants and leisure centres. We don’t only need this type of data in Facebook, we need it in many other parts of our lives, so Facebook have been exploring how to share data with the community-maintained OpenStreetMap. That will help everyone using the thousands of services that use OpenStreetMap. The Facebook users are not in control of this flow of data but they, and many other people, will benefit.
In other sectors rather than downloading data I can give a third party that I trust the right to access it
In other contexts then Facebook users might want to share content that they post with a third party that they trust.
I might decide to do this so that it benefits my local community, for example helping local government understand feelings on a particular topic, to help deliver another service I want to receive, for example by asking my friends if they want to join me on a a new photo-sharing service, or to help me learn things about my own behaviour and habits.
Unfortunately despite Facebook telling me that I can control how data is shared I can’t easily share that data with third parties.
Facebook allows people to download data they post, but it is not in a standard format and I can’t simply give another organisation that I trust the right to access it to the same extent that, say, the UK banking sector is starting to do.
The UK’s banking sector is expecting to see increased competition and new services as a result of making it easier for people to share data. Perhaps social media firms and the people who use their services would benefit from a similar collaborative effort to determine how to safely share data, which mostly includes other people, without creating adverse impacts.
It is good that Facebook is starting to share data to create benefits outside of their own service. They should do more of it by sharing carefully anonymised data openly, more sensitive data in secure conditions with researchers working for the public good, and by giving people ways to safely share data that they post with third parties that they trust.
Explaining this stuff is hard, but it is necessary
This stuff is complex and can be hard to explain in an accessible way, but it is necessary to understand the complexity before trying to make it simple.
Like many other types of content and data, Facebook posts and photos can be about more than one person. The content can create adverse impacts for those other people but it can also create benefits too. Because of this, users are not fully in control of the content they post, and they certainly don’t own it in the same way that we might own a house or car. Instead civil society, governments and service providers need to work together to design ways to help give people more control and to maximise the social and economic benefits, while minimising the adverse impacts.
Over-simplifying this necessary complexity risks us slipping into a world where instead individuals fully control the data that they create. That is the world that Facebook’s ad is describing to many people. How silly. That world will reduce the benefits and increase the risk of harms.
We don’t need more lengthy and unreadable terms and conditions but as the debate over data grows it would be helpful if major service providers like Facebook took greater responsibility in helping to create a more informed debate and helping people to make better decisions.
I was home recently and took my sister’s dog for a walk. When we were young we had dogs, Spud and Gyp, so it was a walk I’d taken before. A few things had changed. One was that there was less dog poo.
Me (left) taking my sister’s dog for a walk around Fairhaven Lake.
It was strange comparing the memories of those messy streets, including muck left behind by Spud, to the reality of the present day with dog walkers cleaning up and signs warning of penalties if they did not. There has been a change in our social norms. In return for the right to walk a dog, most people now accepted they needed to clear up behind them.
My day job is doing policy for the Open Data Institute. Policy is about changing outcomes, hopefully for the better.
On their own, legislation and guidance won’t fix challenges like data ethics, making data as openly available as possible, or the many other complex challenges that limit the social and economic value that societies get from data. It will need social change too.
I’m interested in how that change happens, including how society decided dog walkers should clean up the dunghills created by dogs.
People like having dogs, but dogs make a lot of shit
It would take a lot of rain to clean up 500,000 pounds of dog feces. (image Taxi Driver, copyright a big film company)
People like having dogs (*). They like having a companion. They like going for walks. Dogs can make people feel safer, particularly in a city that had as high a crime rate as 1970s New York. But dogs make a lot of shit (**).
In 1974 New York City’s Bureau of Animal Affairs estimated that 500,000 pounds of dog faeces were hitting the streets every day. The city’s population was growing. More people meant more dogs, more dog excrement and less space to step around it. That affected not just dog walkers but everyone else using the streets.
This sounded analogous to the interweb’s superhighways. While some people are having fun, other people are stepping in the dog doo-doo we make. I read on.
The dog doo-doo battle of many armies
There was a long battle to clean up New York City, it lasted for most of the 1970s. The battle involved many familiar armies.
There were a mix of civil society groups in the battle. Some wanted cleaner streets, others just wanted to keep walking their dogs, and some saw the opportunity for self-publicity. There were also people who didn’t care about the battle being waged under their feet.
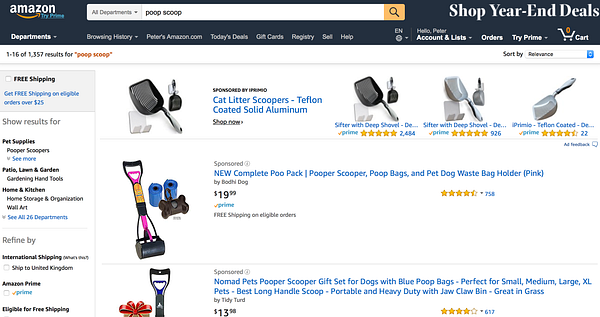
A search on Amazon shows 1,357 results for ‘poop scoop’
There were businesses in the battle too. Some businesses simply wanted cleaner streets outside their shops. A pet food association objected to the final legislation because of the impact it might have on their customers, dog owners. Other businesses saw new opportunities. There was a boom in innovative, and probably disruptive, dirt cleaning solutions that continues to this day.
Different government organisations took positions. In 1970 a new city Environmental Protection Agency had been created. Its leadership saw the opportunity to clear up a problem affecting citizens. Other organisations didn’t want the cost of enforcing new legislation and argued for others to take the lead.
Some organisations seemed to see a chance to pass part of the cost, and blame, for cleaning the streets to dog walkers. I suspect many other government organisations were wondering why all this effort was being spent on canine coprolites.
Meanwhile politicians were trying to navigate between all of these interest groups to tackle both this problem and others facing the city.
Politicians talking crap
Throughout the 1970s some argued that people could be persuaded to change behaviour without legislation through campaigns and leaflets. Both civil society groups and government organisations tried to do this and had some effect in parts of the city.
Others said dogs should use bathrooms in houses, use different sides of the street on alternate days, or even be banned from the streets altogether. The mess caused by dogs risked all the enjoyment being taken away.
Some dog walkers, government organisations and politicians said that it was government’s job to scoop the poop and that government should have more resources for street cleaning.
There were politicians who thought that no legislation was needed as other problems took a higher priority. One politician said that he was keen for the legislation to happen as it would encourage city staff to focus on dogs rather than car parking fines. All politicians were heavily lobbied, by dog lovers and dog poo haters.
I can see a common pattern here. Regardless of whether the policy is about data or doo-doo we need public debate to gather ideas and decide who has to do what, what resources they have to do it with, and whether they get paid for the doing.
There was a campaign over public health issues with statements that an illness called toxocariasis, which can be caused by worms in dog excrement, was causing loss of eyesight in children. This risk appears to have been significantly overstated, although it looks like incidents of toxocariasis are reducing in the UK since dog waste laws were introduced there, but it was an effective campaign.
The debate raged until Ed Koch became Mayor and took a different tack. Rather than having another go at getting a new law passed in New York City’s legislature, he took the problem to the politicians at the New York State Senate. At the state level politicians debated how different solutions are needed in cities to more rural areas and passed legislation that only affected large cities (***). The law gave the city the power to fine people who didn’t scoop their pooch’s poop.
In all policy work sometimes you have to explore a few paths before you get to your goal.
Clearing up dog shit is good for society
Throughout the debate there was a common thread. A city that welcomed dogs but that had less dog faeces scattered around would be a better city.
Dog owners enjoyed the company of their dogs, but other people in their local communities were affected by their enjoyment. Pavements, or sidewalks in NYC, are shared spaces. Use and misuse of that shared space affects everyone who lives in the city. After a debate dog owners were prepared to take on the task of clearing up some of their mess for the benefit of wider society.
A super pooper scooper sign in North Vancouver communicating the new social norm in multiple languages. Image via “New York’s poop scoop law: dogs, the dirt and due process” by Michael Brandow
It is hard to know what was most effective — the debate, the civil society campaigns, the leaflets and signs, government loudly declaring that it had legislated, or the final push of fines. I’ve struggled to find good crap data. But the repeated legislative battles show us that NYC policymakers thought a law was required.
The shift from the streets and dog walkers of my childhood to one where only 3% of British people will not pick up dog poo is a significant change for the better (****). That is social change in action. Social change that made my walk a bit easier. Even though I now had to clear up after my sister’s dog everyone, including me, could enjoy the park a little bit more.
But, does this tale teach us how to make data better?
A crap analogy
Well, not directly. The title of this blogpost wasn’t a joke. It is a crap analogy. Our motives for using data are different from the simple motives — have fun, feel safe- of walking a dog. Data is not like doggy doodah.
While data is not like doggy doodah, Misha Rabinovich has shown that you can use data about faeces to make art. This artwork is temporarily installed at the Open Data Institute for a 2018 exhibition. I wonder if it subliminally got me thinking about this blogpost.
We can all agree what dog poo is, but we cannot all agree on the mess being created by how people are collecting, sharing and using data. We haven’t reached an agreement on what ‘good’ looks like and what outcome we are trying to achieve.
Meanwhile although the data ecosystem contains many of the same actors — individuals, civil society groups, businesses, and government organisations — each with their own changing motives and power it is more than a physical city. There are multiple virtual global villages which manifest themselves in our physical towns, cities, nations and continents. Someone in the UK can create mess on a virtual street used by people in Uruguay, the Ukraine and Uganda. It is trickier to deliberately change social norms and create better outcomes in such a complex system.
But the tale should remind us that given time and effort people are willing to change behaviour and reduce the negative impacts they have on other people. Do you need a New Year’s resolution for 2018? Let’s keep having fun with data, but let’s think more about other people and clean up some of the shit that we’re creating.
(*) and other pets, such as cats, that also lead to interesting tales about data
(***) UK politicians and dog waste policymakers would possibly benefit from reading that 1978 New York State Senate debate as it seems that UK is still discovering that while bagging it and binning it works in cities, in more rural areas you need to stick it and flick it.
(****) despite the improvements some people want city streets that are completely clean of the odious dog ordure. You will regularly see news articles about towns and cities saying that they might use CCTV tracking, registration schemes, and dog DNA databases to catch offenders. A company called MrDogPoop claims to have “the most powerful Dog Poop DNA matching database in the world” to help track down poops that avoid the scoop. These city-wide schemes tend to disappear when people realise the cost and debate uncovers that a rover registration scheme is too much of a stretch to our social norms.
I’ve been asked to do a talk about “data and policy”. First, an apology. I don’t speak Dutch and sometimes I speak English too fast, and sometimes too quietly. That makes it harder for people who don’t speak English as a first language. Sorry. Shout at me if I do that and I’ll speak more clearly.
I want to start by expanding on the word policy. It means different things in different contexts.
Merriam-Webster has a definition of policy that says “a high-level overall plan embracing the general goals and acceptable procedures especially of a governmental body”.
That is a classic definition but there are other meanings and contexts.
Within organisations there will be policies for compliance with data regulation, like GDPR, or for how data should be collected, used, stored, shared or opened. Businesses, civil society and not-for-profit organisations will also have public policy positions on “government policies that affect the whole population”.
At the Open Data Institute lots of members of the team deal with all of these meanings of policy in different contexts. Most of my work is on public policy, but I’m trying to influence both governments and businesses.
The ODI is not-for-profit. We work globally, our headquarters are in the UK. We were founded by Sir Tim Berners-Lee, the inventor of the web, and Sir Nigel Shadbolt, an AI pioneer. We are not partisan but we are political. Data is a political topic. Open is a political statement. Our mission is knowledge for everyone.
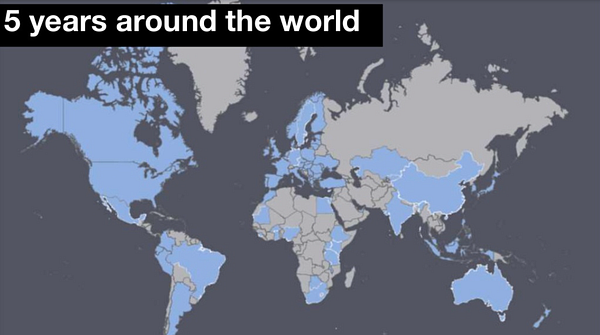
A (hopefully) comprehensive map of where ODI has done work, where nodes have formed and where members are.
It’s our 5th birthday this year. Yay us 🙂 I’m going to share some policy lessons from those 5 years. The lessons have been learned from our work around the globe, our peer network of nodes and our network of members.
Policy is one of the capabilities we use to help us deliver our mission and strategy. We also do a lot of work with technology, training people, gathering evidence, building communities and incubating startups.
First, let’s talk about open data. Open data is vital and incredibly important but we learnt that if we only talk about and use open data then we can’t deliver our mission. Instead we work across the data spectrum.
The data spectrum is about access. Who can get to data so they can use it or share it or etcetera. Some data should be kept closed within an organisation, like sales reports. Other data should be shared: the police need to be able to see your driving licence, medical records can help with research, twitter data can help us understand how social media is impacting our societies. Lots of data should be open data, things like bus timetables, maps and addresses.
At the ODI we learnt that we need to talk about and use the full spectrum of data to both get more open data and deliver on our mission.
We also learnt that we need to combat the very strange view that data is oil or coal or other types of fossil fuels.
I can, and often do, talk in economic theory about the different qualities of data and oil, but there is a more important difference. It creates the wrong mentality. People fight over control of oil. They want to hoard it for themselves. They want to sell it for huge amounts of money. This is not the way to get the most value from data, an increasingly abundant resource. The thinking generated by treating data like oil reduces innovative use of data and causes loss of trust by societies in how data is used.
Instead we need to turn data into infrastructure. It is already heading in that direction but we need to strengthen that momentum. Great infrastructure is boring, reliable, safe and easy to use. It’s there when we need it. Data is decades away from being boring, trust me *pause for ironic, self-knowing laughter*, but that’s the direction to head in. Turning data from every part of society — especially the public and private sectors – into safe, trusted and easy to use infrastructure that underpins every sector of our economy and our societies.
And that infrastructure will be built on a foundation of datasets that are made available as open data, for anyone to access, use and share. That foundation of open data makes it easier to publish and use other data.
The third lesson is about goals. Sometimes it can feel to other people like the goal of the open data movement is only to publish more open data or to put data on portals. That’s the wrong goal.
We think, talk about and use open data as a tool. One of several tools in the toolbox.
A toolbox that we, and others, use to tackle problems. Like finding a job that you enjoy, combatting corruption, finding your way around a city, responding to the threat of anti-microbial resistance, helping with house planning and building, or understanding the growth of new sectors and business models like the sharing economy (something we’re looking at in our new R&D programme).
The fourth lesson is about chance. Chance is great. Very unexpected things happen when you open up data. One of my personal favourites is that the UK government opened up radar data that was originally gathered for planning flood defences and people used it to discover both new places to grow wineand new Roman roads that criss-cross parts of the country. Fantastic. But that doesn’t always work.
Instead we learnt that we need to put more focus on creating impact by design. Looking for problems, working with people who are experts in tackling it and helping them to use data as one of the tools in their toolbox. When we do that then chance can also happen, but we also have a much higher chance of impact, and impact is necessary for sustainable change.
So those lessons are some of the ways we learnt to think about data over the last 5 years — about the full spectrum of data, about data as a tool, about impact by design, and about data as infrastructure. Those mental models are part of our approach to public policy.
But through our work and delivery we have also learnt some of the most effective levers that we have to create impact. In our policy work we amplify those levers and encourage others to use them or build their own.
First, practical advocacy.
Over the years we’ve developed a set of guides and a toolbox. They’re openly licenced. Anyone can use them, or fork them and change them. That can be a challenge for an organisation that needs to bring in revenues but it’s the right thing to do for a mission with an an open culture and a big mission. We don’t want to do everything, even if tried we wouldn’t be able to. We want to make it possible for other people to do what we do.
The practical advocacy tools keep on expanding.
We recently launched the first version of a data ethics canvas to help organisations using data understand, openly debate and decide on ethical issues about collecting, sharing and using data. Interestingly when we looked into data ethics we found that most of the debate was about personal data in the closed and shared parts of the data spectrum. People had missed the ethical issues around open data and non-personal data. The canvas might help fix that.
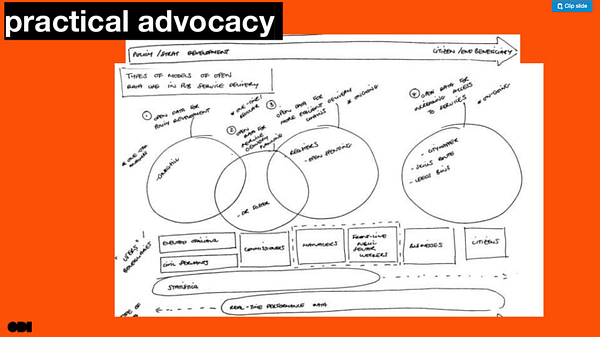
As part of our research & development programme we’re exploring how open data is being used in public sector service delivery and how it could be used more. There are some famous stories about open data helping to reimagine public services but we are still seeing the same old stories and not enough momentum. We’re hoping that through our research we can help understand the barriers to change, and build some methods and patterns that will help people do more things to use data to improve public services.
Patterns are important. We’ve also developed a set of design patterns for policymakers that use data to help them create impact. While data policy people might know data, many other policymakers don’t. We need to reach them and put data into their context, in language they understand and helping them understand how it can help them tackle their problems.
Through approaches like evidence-based policy many policymakers have realised that data can help inform policy, but these patterns also help show policymakers how data can help deliver policy. Whether that policy is reducing costs, improving an uncompetitive market, or helping consumers switch between service providers.
The next big lever is networks, peer networks in particular.
Peer networks are horizontal organisational structures with members who share similar identities, circumstances or contexts. We run global, African and European peer networks for open data and have seen their power in developing learnings and creating change. We’re learnt from how they have grown and how the people in them interact.
We’ve been seeing peer networks start to emerge in other work they do. Things like ODINE (open data incubator Europe), Datapitch (another Europe-wide startup incubator), and the sector programmes.
We believe that fostering other peer networks: in sectors, in particular disciplines (like policy), or in particular geographies will help build a better future faster. We’ve published a method report that we, or others, can use to do that.
Finally, sector programmes. We’ve been working with whole sectors to help them work together to use data. We can get more done if we work together.
Most people are familiar with organisations like the Open Government Partnership. Less well known are groups like GODAN (the Global Open Data for Agriculture & Nutrition) initiative that brings together governments, businesses and farmers to open up agriculture data to solve problems.
OpenActive is opening up sport data to make people more physically active. Places that offer a whole range of sports: football, squash, badminton, table tennis, running are opening up data and they’re also building an ecosystem of organisations that will use that data to make it easier for more people to play the sports they love.
In an initiative called open banking the UK retail banking sector is opening up data about products, locations and cash machines and creating open APIs so that people can choose to share data held about them by banks with people that they trust. We hope it will make it easier for more people to create better services for bank customers. It could also improve national statistics, help improve the UK’s identity framework, help tackle financial inclusion or many other things. We’re talking to other countries on multiple continents about helping them implement open banking too.
There are more sectors, like transport, coming together as they start to see the power of working together to solve common problems. We need to encourage sectors to understand and unlock the value of open data by focussing on infrastructure, skills and open innovation.
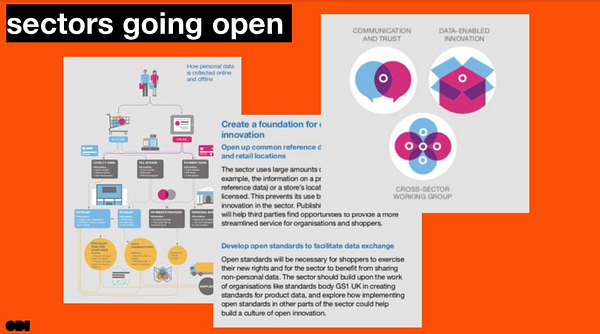
Finally, we’re launching a report today on the grocery retail sector and GDPR based on consumer research, sector interviews and our thinking about sectors. We want to encourage the retail sector to work together to focus on opportunities, and to use the data they hold in ways that both builds trust in shoppers and gives them better services.
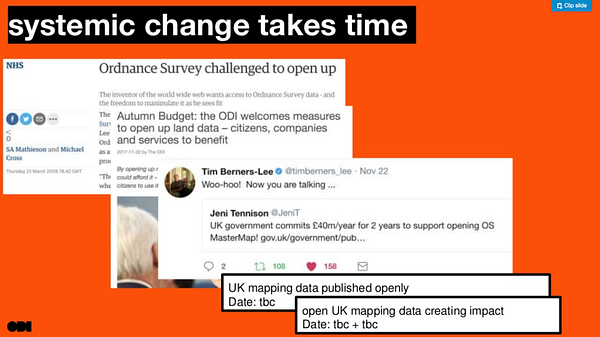
But there’s an important point to understand with all of these levers. We are not building a new product or smartphone game. We are changing systems. This takes time. We are only a few decades into a large wave of technology driven change that will take many more decades to see through to the end.
And that’s why there’s another vital lesson. Having fun. Being optimistic. Sometimes it can feel like things are moving slowly or in a bad direction and that things will never get better. But just as open is a political statement, so optimism is a political act. Having fun helps me be optimistic. Choosing to be optimistic both helps the day go faster and creates the momentum we need to help create a better future.
Approximate words of the talk I gave at the EU datathon in November 2017.
Hi, I’m from the Open Data Institute, or ODI. I’ve been asked to do a quick talk before the next panel about “open data and advocacy”. I’ll keep it quick so you can get to the panel and the Q&A. Asking questions is much more fun than listening to a presentation 🙂
We’re a not-for-profit. We work globally, our headquarters are in the UK. We were founded 5 years ago by Sir Tim Berners-Lee, the inventor of the web, and Sir Nigel Shadbolt, an AI pioneer. Our mission is knowledge for everyone.
As you might have seen on the first slide it’s our 5th birthday this year. Yay us. So, I want to share a bit about what we’ve learned about advocacy and open data in that time.
First, let’s talk about open data. Open data is vital and incredibly important but if we only talk about and use open data then we can’t deliver our mission. Instead we work across the data spectrum.
The data spectrum is about access. Who can get to data so they can use it or share it or etcetera. Some data should be kept closed within an organisation, like sales reports. Other data should be shared: the police need to be able to see your driving licence, medical records can help with research, twitter data can help us understand how social media is impacting our societies. Lots of data should be open like bus timetables, maps and addresses.
We need to talk about and use the full spectrum of data if we were to get more open data made available so that anyone can access, use and share it.
The second lesson is about goals. Sometimes it can feel to other people like the goal of the open data movement is only to publish more open data or to put data on portals. That’s the wrong goal.
We think, talk about and use open data as a tool.
A tool that we use to solve problems. Like finding a job that you enjoy, combatting corruption, finding your way around a city, responding to the threat of anti-microbial resistance, helping with house planning and building, or understanding the growth of new sectors and business models like the sharing economy (something we’re looking at in our new R&D programme).
The third lesson is about chance. Chance is great. Very unexpected things happen when you open up data. One of my personal favourites is that the UK government opened up radar data that was originally gathered for planning flood defences and people used it to discover both new places to grow wine and new Roman roads that criss-cross parts of the country. Fantastic. But that doesn’t always work.
We need more focus on creating impact by design. Looking for problems, working with people who are experts in tackling it and getting them the data they need. To move data to the right place on the spectrum. When we do that then chance can also happen, but we also have a much higher chance of impact.
We also learnt that we need to combat the very strange view that data is oil or coal or other types of fossil fuels. I can talk in economic theory about the different qualities of data and oil, but there’s a more important difference. It creates the wrong mentality. People fight over control of oil. They want to hoard it for themselves. They want to sell it for huge amounts of money.
Instead we need to turn data into infrastructure. It is already heading in that direction but we need to strengthen that momentum. Great infrastructure is boring, reliable and safe to use. It’s there when we need it. Data is decades away from being boring, trust me *pause for ironic, self-knowing laughter*, but that’s the direction to head in. Turning data from the public and private sectors into infrastructure that underpins every sector of our economy and societies.
And that infrastructure will be built on a foundation of datasets that are made available as open data, for anyone to access, use and share. That foundation of open data makes it easier to publish and use other data. It’s a powerful way of thinking.
So those lessons are some of the ways we learnt to think — about the full spectrum of data, about data as a tool, about impact by design, and about data as infrastructure. Those mental models have helped our advocacy.
But over the last five years we have also learnt some methods that work to create impact.
We’ve been working with whole sectors to help them use data.
The UK retail banking sector is opening up data about products, locations and cash machines and creating open APIs so that people can choose to share data held about them by banks with people that they trust. We hope it will make it easier for more people to create better services for bank customers. We’re talking to other countries on multiple continents about helping them to make the same change. GODAN (the Global Open Data for Agriculture & Nutrition) initiative that we work with is working globally to open agriculture data to solve problems.
OpenActive is opening up sport data to make people more physically active. Places that offer a whole range of sports: football, squash, badminton, table tennis, running are opening up data and they’re also building an ecosystem of organisations that will use that data to make it easier for more people to play the sports they love.
There are more sectors, like transport, coming together as they start to see the power of working together to solve common problems. We need to encourage sectors to understand and unlock the value of open data by focussing on infrastructure, skills and open innovation.
We’re launching a report next week on the grocery retail sector and GDPR based on consumer research, sector interviews and our thinking about sectors. We want to encourage the retail sector to work together to focus on opportunities, and to use the data they hold in ways that builds trust in shoppers and gives them better services.
As well as sector programmes we work on practical advocacy. Here’s two examples.
A data ethics canvas to help organisations using data understand, openly debate and decide on ethical issues about collecting, sharing and using data. Interestingly when we looked at data ethics we found that most of the debate was about personal data in the closed and shared parts of the data spectrum. People had missed the ethical issues around open data.
We’ve also been working on networks. Peer networks are horizontal organisational structures with members who share similar identities, circumstances or contexts. We run global, African and European peer networks for open data and have seen their power in developing learnings and creating change. We’re learnt from how they have grown and how the people in them interact.
We’ve been seeing peer networks start to emerge in other work they do. Things like ODINE (open data incubator Europe), Datapitch (another Europe-wide startup incubator), and the sector programmes.
We believe that fostering other peer networks: in sectors, in particular disciplines (like policy), or in particular geographies will help build a better future faster. We’ve published a method report that we, or others, can use to do that.
Oh and finally, there’s another vital method. Having fun. Sometimes it can feel like things are moving slowly or in a bad direction and that things will never get better. But just as open is a political statement, we should also be aware that optimism is a political act. Having fun helps me be optimistic. Choosing to be optimistic both helps the day go faster and helps create a better future.
Thank you. I hope this talk and the rest of the event is both fun and useful.
A new report by Webroots UK on the cost of online voting in UK national elections was published last week. The report was backed by politicians from four large political parties — Labour, Conservatives, SNP and the Liberal Democrats. It is about one of our most fundamental democratic rights. It deserves debate.
The report argued that online voting would increase the number of voters and reduce costs by 26% per vote. Unfortunately it missed significant risks and argued for saving costs by making it harder for millions of mostly disadvantaged UK citizens to exercise their democratic rights. Rather than arguing to reduce the cost of democracy, we should be arguing to make it better.
The risks and decisions of online voting
One of the classic lines about online voting is that people can safely bank online so they should be able to safely vote online. An analogy that sounds useful but is unhelpful. Banking and voting are very different problems, carry different risks and societies make different decisions about them. To give three examples.
We are comfortable that banks and governments know us and can see how we spend money but want our votes to be secret. We choose to accept the risk that governments and banks might mistreat our finances, but are prepared to accept very little risk that governments and people might mistreat us because they know how we voted.The damage that could be caused is bigger and harder to undo. The risk is higher.
Meanwhile the damage caused by mistakes or manipulation of national elections is higher than in other types of election. The reward for successfully manipulating a national election will attract malicious attackers who will act for their own reasons at their chosen time.
Finally, there are risks alongside online voting. Multiple countries have seen online social media used to spread disinformation during elections. We are only just starting to understand how this happened, let alone understand the damage and what actions could reduce it. There is a risk that online voting will provide new ways for disinformation to have an impact.
These are the type of risks that people who want to introduce online voting for national elections need to consider and debate with society. We should make conscious decisions on whether or not to accept them.
4.7 million people or 15.2 million people
But even if we find an acceptable le online voting safe, or choose to accept the risks, there is another implicit argument in the report. That online voting will make it easier for up to 4.7 million people and reduce costs by making voting harder for up to 15.2 million people.
The report used a survey to argur that online voting would increase the number of voters by up to 4.7 million. These are people who do not currently go to polling stations (the places where people can vote in person) but would vote online. This would lead to a cut in administration costs by reducing the number of polling stations or reducing mailing costs by moving election material online. We will need less of these as some people vote online.
It failed to discuss how many people do rely and will continue to rely on paper voting and electoral information. As the UK’s Goverment Digital Service recently said “paper isn’t going to go away”.
A report published by the Good Things Foundation said that 15.2 million people in the UK are either non-users, or limited users of the internet, that 7.5 million of those people are under the age of 75, and that 90% of non-users can be classed as disadvantaged.
The cost reduction measures in the Webroots report will make voting harder for these millions. They will have further to travel and find it harder to get information about who to vote for.
Politics is about choices. What gets done and what does not get done. Who wins and who doesn’t. I’m surprised that politicians from these major parties appear to favour the advantaged over the disadvantaged. Why they find it appropriate to reduce the quality of service for so many.
Rather than arguing for an online service or cost reduction, argue for a better service
The Webroots report is fundamentally starting from the wrong place. It is arguing for an online service that will reduce cost, rather than arguing to improve the quality of service. Unfortunately this is a common approach when using modern technology to improve existing public services.
The UK Parliament’s new e-petitions service only offers the ability to share a petition via social media and provides no way to combine online petitions with paper petitions that are hand-signed in communities. While the logical conclusion of wanting to make elections cheaper is to simply “do less” and cancel elections. Perhaps we could use an algorithm and some data.
Doing the hard work of research and experimentation to discover how to improvr democracy using modern technology in a number of ways, as organisations like Democracy Club do, is more useful.
We will find that we can and should use modern technology to improve democracy for everyone such as through online voting, better designed forms, making it easier to find a polling station, tools to help polling station staff, and a whole host of other things that might make democracy better.
As we make those improvements we should take the opportunity to have a more informed debate over the risks and who benefits, but we shouldn’t focus solely on online services and cost reduction we should make democracy better for everyone.
Some of the changes which people have told us would make registering to vote and voting easier would cost more money. But we would like to see things changed so everyone can register to vote and vote.
As I’ve been starting to get to grips with technology policy over the last few years one of the things that has fascinated me is how little reference to history there is. When I read historical books and talk to people about technology and innovation history I find some frequent gaps. We need to learn from history if we are to make the best of the opportunity created by the current waves of innovation and technology.
For example, people talking about the wonders of technology talk about how few staff WhatsApp had when they were bought by Facebook, yet don’t talk about how few people sailed in the Niña, the Pinta, and the Santa Maria when Columbus sailed across the Atlantic. After Columbus’ expedition more and more people crossed the Atlantic, for exploration, for business and for pleasure.
WhatsApp’s success built on the internet, the web, cryptography and smartphones. Similarly Columbus relied on inventions in navigation and shipbuilding. Neither could have achieved what they did without those previous inventions. Are they analogous?
Learning lessons from history
Recently I read a couple of books that helped me sort out some of my thinking about lessons from previous waves of technology-driven change. The books were Ruling The Waves by Deborah L. Spar and The Master Switch by Tim Wu. They are good books. If you’re interested in technology policy you should read them too. I’ll lend you my copies if you want.
Ruling The Waves uses ocean sailing, telegraph, radio, satellite television, cryptography, personal computer operating systems and digital music to explore innovation. It proposes that they show four common phases: innovation, commercialisation, creative anarchy and rules. Different actors dominate in each those phases.
There are piratical adventures in the early years before the surviving, and now dominant, winners encourage government to work with them to bring order to the new technology. Using the model of this book would show that my silly Whatsapp/Columbus analogy is fatally flawed. Columbus was in the innovation phase, Whatsapp (and other messaging services) are in either the creative anarchy or rules phase. They’re very different kinds of innovators.
Ruling the Waves argues that the eventual rules tend to be dominated by intellectual and property rights. It shows that it can take decades, or even centuries, from innovation until stable rules are in place.
The Master Switch looks at lessons from the telephone, radio, broadcast and cable television, and Apple to propose that all information technologies go through a cycle of decentralisation to centralisation ending with a corporate (or state) monopoly where innovation, the economy and consumers suffer.
It argues that a separation principle can help prevent this fate.
This principle would keep a distance between young industries and existing monopolies to enable new technologies to show their worth; between different markets to make it harder for monopolies to spread; and between the public and private sectors to prevent government from favouring friendly monopolies.
After reading the books I was more convinced than ever that the waves of change bought about by the internet and web will take decades, if not centuries, to be absorbed into our societies. It is seductive but false to think that we can legislate for technology and data quickly. We have to allow for experiments to learn the right legislative and regulatory frameworks.
Gaps in the lessons
But there were gaps in the books. That’s not unique. I see the same gaps in lots of technology policy and thinking.
Despite the best efforts of Victorian inventors the vast majority of dinner tables do not yet feature a minature railway delivering food to bearded men. Picture from Victorian Inventions by Leonard de Vries
Major enabling waves of technology like the internet and web underpin lots of other innovation — like smartphones, social media and search engines—that each have their own journeys to go through. Some of these smaller waves will have lasting impact, some may disappear and get washed away, others are badly timed and will come back in a while. But the waves don’t stop. They are continuous. That is one of the reasons why open culture is so important. It keeps us open to innovation, new ideas and challenges from outside of a small circle of friends and organisations.
Both books miss the impact of data in the current period of change and that much of this data is personal data. It is data about you, me and billions of other people. Most data is about interactions between people, or between people and organisations staffed by other people. It is difficult, if not impossible, to determine who ‘owns’ data. For most data there will be multiple people and organisations who have rights. This makes it hard to rely on property rights as a way to shape and bring rules to the market. The challenge of building good governance for data infrastructure will need a more systemic response than property rights.
The books also focus on the US and UK, with some excursions into mainland Europe. While they describe the differences between European and US approaches to regulation, with Europe typically intervening more, I would love to see more about the lessons learned by other countries. The web, the internet and data infrastructure cross, and therefore soften, national boundaries. Learning from and listening to other countries and societies will become even more important as these waves of technology reach their full power. These excellent recent reports from the Web Foundation are useful for those in a US/UK filter bubble who want to start listening more widely.
Innovation has limits
And finally both books miss the influence of societies and people. They are books about economy, regulation and business. They miss the social side of the change.
Lots of the impact of technology is societal as well as economic. Similarly the forces that impact on and affect technology change are both societal and economic. People adapt to technology and innovation, but sometimes they push back and reject it. Those rejections can be learned from.
The innovations that led to Christopher Columbus crossing the Atlantic also led to industrialised slavery. Slavery might have helped create the modern world but it is an evil that should not have happened and should not still be happening. We could have intervened earlier and stronger to stop it. A modern world similar, but not the same as, our current one would still have been built. It would have taken longer but it would have damaged billions fewer people in the process. Our societal norms now reject slavery and many of the other things that that particular innovation enabled.
As our societies matured we embedded some of those societal norms and values into legislation. Human rights, worker’s rights, anti-discrimination, health and safety, and data protection are some obvious examples. They are strong signals from society indicating where innovation is encouraged and where it isn’t.
The precise rules will vary by country but while the boundaries of legislation will contain things that need to adapt as we learn how to do things better at the core of the legislation are societal norms and values. We cannot and should not forget our values as we go through this wave of change. Those values do change but that change should be vigorously and openly debated.
Innovation can take strange paths and be used for unintended purposes. We need to engage and work openly with societies and people if we are to both understand the limits and share the benefits of the current waves of technology.
What does this have to do with my job?
Over the last couple of years I’ve been working at the Open Data Institute where I spend about 50% of my time working with the private and public sectors delivering projects and building services. We help businesses and governments understand and adapt to the wave of change being bought about by data. The other 50% of my time is spent developing our policy thinking based on what I and the rest of the team and network learnt from delivery and research.
Clearly data is not “good” infrastructure right now, too many people can’t get the data that they need, so we think a lot about how governments and businesses can help strengthen it. We look at history when we do that. This is all part of my research. How did we recognise things becoming infrastructure in the past? How did we learn how to design and build good infrastructure? How long did it take? Do historical examples contain useful lessons?
What should I read next?
Anyway, like all of my blogs, I’m thinking out loud. These are some of the things my recent work and reading about history has made me think about. The gaps in the last two books led me to pick a book on the anthropology of roads as my next one. What should I read or who should I talk to after that?
Hello. This is the personal website of Peter K Wells. I do politics, policy and delivery to try to make data and technology benefit everyone. I also do bad jokes and music references.
This website stores cookies on your computer. These cookies are used to provide a more personalized experience and to track your whereabouts around our website in compliance with the European General Data Protection Regulation. If you decide to to opt-out of any future tracking, a cookie will be setup in your browser to remember this choice for one year.