The survey is not particularly easy to respond to, for example it asks people to provide information about all of the public sector data they use. That would be a lot of information for many organisations and people!
There is a page listing all of questions and a separate page with an online survey to answer the questions. It does not say that you can email answers to the team so I would recommend filling in the online survey.
If you focus on the key questions 12-14 it might only take about 5-10 minutes. You can save progress as you go, but you can’t change your answers once you have submitted the questions
I recommend that you respond politely and honestly throughout. Do use your own words and thoughts. In case it’s useful to help your thinking then here are some tips on what to expect and how I responded.
Questions 1-7 are about your organisation and job.
I both work with multiple organisations / sectors and use data as a citizen so found this section confusing as it assumes people only use data for a single organisation. Others may find it simpler.
Questions 8-11 are about public sector data you use in your work.
Again, it wasn’t obvious how to answer these. I use, experiment with, imagine, and campaign to improve lots of data. But this wasn’t why I was responding to the survey and it wasn’t clear what this information would be used for.
So I kept it simple and skipped questions 8 and 9, they’re optional questions, and answered don’t know/other to questions 10 and 11 as they are both mandatory questions.
In response to question 11 I gave a couple of suggestions of other issues that affect both businesses and individual citizens, specifically “inability to contact data holder” and “inability to request data corrections”.
Questions 12-14 are about existing public sector data sets that you or your organisation would like to access that you currently do not. This is where I chose to respond about address data
For Question 12 I responded “Administrative address and mapping data created and maintained by public sector organisations as part of their public task“.
Question 13 is about the access issues. I responded with “Cost”, “Data Quality” and “Legal Frameworks”. In the “Other” section I gave a short description of the legal risks and current business models, saying:
“1. The intellectual property status of many public datasets that contain this data is unclear. This is because of unclear licensing and derived database rights. Public sector organisations can interpret this situation differently, for example Ordnance Survey’s recent contact with 34 local authorities https://www.owenboswarva.com/blog/post-addr44.htm. This risks a chilling effect where people are unwilling to invest to innovate.
2. Some of the public sector organisations that create and maintain this data, for example the Ordnance Survey, are run as government companies. This creates an incentive to protect their rights and monetise the data, rather than to maximise the public good. They should instead be funded to publish this data for free.“
Question 14 is about the benefits. I responded:
“Address data, and geospatial data more broadly, are foundational datasets that are used extensively across the public and private sectors.
There are many current use cases that would be improved by making the current datasets freely available under an open licence; use cases that will be improved because effort and money that is currently spent buying datasets and understanding licences will be spent on other more useful activities, and new use cases that will be created by innovators – in the public, private and third sectors – who currently feel hindered by the cost and/or legal uncertainty.
The EU estimates it will receive up to €2 billion per year in economic growth from making this data available for free under an open licence. “
Questions 15-16 are about new datasets that the government could collect.
I chose not to respond on these topics in this survey.
Questions 17 – 19 is about public sector data that would help people develop or use AI.
My response to question 17 pointed out the existing set of complex copyright questions about data and AI and how open data would help:
“Publishing address data, and geospatial data more broadly, as open data for free would help me develop or use AI as it will reduce one element of the current complex set of copyright issues that surround AI products.“
Questions 20-21 are broad free-text questions
Questions 22-25 are about staying in touch for more research.
If you care about increasing access to UK address data, or geospatial data more broadly, then this is an opportunity to let the UK government know.
If you focus on the key questions – numbers 12-14 – about existing public sector data that is hard to access then it should only take 5-10 minutes.
If you’re not sure about why this is important then some reasons follow.
If you already know how you want to respond then simply skip directly to this post some tips on how to respond and see the responses I sent in.
Address data is incredibly valuable but too difficult to access
In the UK addresses – for example, “29 Acacia Road, Beanotown” – are maintained by local authorities. The list of address changes as flats, houses and offices get developed and demolished. These local lists are collected into a national dataset and made accessible to other public and private sector organisations.
While this happens address data gets tangled up in a complex web of other organisations who end up holding some intellectual property rights in the data, particularly the Royal Mail and the Ordnance Survey.
The Royal Mail is a business and the Ordnance Survey is a business owned by the government. Because they are businesses their primary goal has become to generate revenue for themselves by selling the data, rather than maximising the public good that could be created from using the data.
This reduces the value that can be created from address data.
In practical terms that reduced value results in worse services. For example more occasions when people struggle to get home insurance, register with a doctor, or apply for a benefit because their address is not recognised by the computers.
At a more societal level it means it’s just that bit harder for businesses to get started or public services to be built. People spend time and effort buying data licences and then paying lawyers to help interpret those licences, when that time could instead be spent building better services for us to use.
So, as well as the poorer services that some people experience, there are other services that simply do not exist because businesses and public service organisations could not build them.
Put together that means lost services, businesses, and jobs.
As a practical example, recently the Ordnance Survey, a company owned by the government, paid their lawyers to contact at least 34 local authorities to ask them to check if they had released a list of addresses in error. Whoever is in the right on the legality of each data release, it’s clearly more public money not being spent on providing public services.
Overall the issues add up to big financial numbers and the UK is increasingly becoming an outlier as other countries make this kind of foundational data openly available for free. The EU has estimated that by 2028, its own plans for the wider availability of geospatial data – including addresses and maps – will generate up to €2 billion per year in economic growth.
So poorer services and weaker growth. Sounds like the UK is missing out by not making its own geospatial data more accessible.
Unfortunately despite the public promises successive governments have failed to deliver change.
Recently the current UK Government even appeared to confirm that the civil service had made no assessment of the potential benefits. Which was surprising. It makes you wonder what people have been doing all of these years.
So will responding to this latest survey change anything?
Honestly, it’s impossible to tell. All most people can do is continue to request and provide evidence of the potential benefits.
If the government, or its civil servants who work on data policy, believe the benefits are not significant then at least this might encourage them to provide their own evidence for public debate or run some experiments that could help the UK learn how to make data more accessible.
After all, addresses and geospatial data are relatively easy to make more available. The potential issues are well understood. The real challenge is modernising government institutions, and that’s a challenge that the current government has said it is willing to take on.
So, let’s ask them to try.
Read on to find out how to respond to the survey and ask for better access to address data.
A picture of some people by L S Lowry (via Flickr)
The committee is currently investigating Artificial Intelligence and whether the existing frameworks and regulations are sufficient to ensure that high standards of conduct are upheld as technologically assisted decision-making is adopted more widely across the public sector.
Big topic. After all AI is a range of techniques that uses people, mathematics, software and data to make guesses at the answer to things. It can help, and hinder, with lots of the huge array of things that the public sector does.
I represented the Open Data Institute (ODI) on a roundtable for this investigation. A couple of people have asked me what the roundtable was like and what I said. Here’s a quick blogpost.
Preparing for a roundtable
The ODI team get invited to lots of roundtables and events. We decide which ones to do and who does them based on a range of criteria. The invitation for this one went to our CEO, Jeni Tennison, she passed it to me to do. My goal was to help the committee, learn from what other attendees were saying, and test some of our ideas in front of this audience.
We did our usual preparation by sharing the questions around the team in the office and telling our network that we were going along to hear what advice they gave us. That technique provides a lot of input. It also helps me represent the ODI and the ODI’s network, rather than simply myself and my own views.
I summarised it down to a few key points to try and make, and then tried not to over-prepare. Over-preparation is the worst sin: it makes me sound even duller than normal.
Rounding a table
The roundtable itself was at Imperial College in London.
The setup was more informal and the committee was more friendly and asked more insightful questions than most similar things I’ve done. That was good. My background is technical and private sector — I previously spent 20 years working with telecoms operators building products, systems and networks — so I always worry that I’ll misunderstand or miscommunicate particular words or phrases. That would damage both me and the organisation I represent.
Anyway, I managed to get over versions of some of things that we’d prepared and/or that we regularly discuss in the office and that were relevant to how the roundtable took shape:
that there is little transparency over use of AI in the public sector and of how the UK government’s Data Ethics Framework is being used. I know that there is good and bad work being done, but mostly because I know some of the people doing it. How are the general public meant to know?
that we need to focus more on the people who design, build and buy AI services. Exploring what responsibility and accountability they should have and how we give them the space, time and money to design those services so that they support democracy, openness, transparency and accountability as well as being efficient and easy to use
that the current focus on ethical principles and AI principles do not seem to be having a usefuleffect. That instead we need to couple those top-down interventions with more bottom-up practical tools (like the framework or ODI’s Data Ethics Canvas) and more research into how the people designing, building or buying AI systems make decisions and what will influence them to comply with the law and think about the ethical implications of their actions
that control, distribution of benefits and harms, rights and responsibilities about AI models would be a useful area to explore
that eliminating bias is the wrong goal. Bias exists in our society, some of that bias becomes encoded in data and technology. AI relies on the past to predict the future, but the past might not reflect the present let alone the world we want. We should build systems that take us towards the future we want, and that can adapt as things change
I also learnt a lot from other attendees with some interesting things for myself and the team back in the office to chew over.
After the roundtable
A couple of weeks after the roundtable I was sent the transcript to review. The committee will publish that transcript openly — which is good and healthy. Attendees get to see the transcript first so they can suggest corrections to simple grammatical errors or transcription problems. That’s why I’m not commenting on or sharing what other people said.
It is important to review the transcript. There are sometimes errors. For example, in this transcript I was recorded as saying that my boss, Jeni, was “whiter than me” rather than “wiser than me”. I have no idea how I’d measure the former but I certainly know that she’s the latter. Some of the words and thoughts in this blogpost come from Jeni and others in the team like Olivier, Miranda, Renate, Jack &c &c &c.
Reading the transcript also helps me understand the difference between the clarity of my speech and the clarity of my writing. I’ve left most of my spoken errors in place. Just like the state we can’t only communicate in words and pictures that are sent through a computer. Most of us need to get better at speaking with humans.
At the Open Data Institute we use a theory of change. It is one of the tools that we use internally to help us make decisions and externally to explain to people what we do and how we do it.
Our theory of change describes the farmland, oilfield and wasteland futures and helps us try to steer between the extremes of the oilfield and wasteland futures to get to the farmland.
The wasteland future emerges when there are unaddressed fears arising from legitimate concerns — such as who has access to data and how it might be used.
We frequently talk through the theory of change to explain what we do and how we do it. We try to provide pauses in the conversation to get other people to give their opinions. It helps people to think and learn for themselves. It helps us learn too. We hear what other people think happens in the wasteland future. How they think people and organisations will react to their fears being unaddressed.
Most of us the people we talk with think that the wasteland future has a lack of data. They realise that with a lack of trust then many people and organisations will reduce how much data they share. They imagine people refusing to use services because they don’t trust them, and that organisations similarly refuse to share data because they fear being punished. They think the data stops flowing.
These tips—based on insurers using social media data to set premiums—are stunningly dystopian. pic.twitter.com/uceFFIThyO
A smaller group of people realise the wasteland is more complex and weird. People’s behaviour will change in many different ways. Humans are fun like that.
Some people might post inaccurate data. Perhaps you will post fake claims of jogging exploits to social media if it is the only way to get a fair life insurance deal. Other people will hide in the data. Maybe we will give our children common names so they are hard to identify or so they appear to be from an ethnic group that is not discriminated against.
I’m sure that even if you hadn’t thought of them at first you can now think of many more things that happen in the wasteland future.
You can see some of this future now. There are already people and organiastion hiding in the flows of data. Some of those people need and deserve help to hide because they have a genuine fear of harm, perhaps due to their political beliefs, ethnicity or sexuality. Equally there are others who are trying to evade fair scrutiny, for example tax dodgers and other criminals, and organisations providing services to help them do so. But if we increasingly fear harm then more people will want and need these services and, inevitably, they will become ever cheaper and used by more of us.
As this behaviour becomes widespread we will see data that is massively biased and misleading. People and organisations that use data-enabled services to tackle global challenges such as global warming, to price a life insurance premium in a way that doesn’t unfairly discriminate, or to decide whether or not to take a job will struggle. That would not be good for any of us.
Navigating the a route between the wasteland future and a different future where we get more economic and social value from data will not be easy. There will always be some people who need to pollute and hide in data to protect themselves from harm, we need to allow that to happen. Understanding and addressing people’s fears is not only a technical challenge, it is also a social and political one. To retain trust we need businesses and governments to adapt to people’s ever-changing expectations in a range of cultural contexts.
An increasing fear of how data is used will not simply stop people using services or sharing data, it will change peoples behaviour in a range of ways. If that happens we can expect data to be increasingly poor quality, biased and misleading. And that pollution will make data less useful to help people, communities and organisations make decisions that hold the potential to improve all of our lives. Some of that potential is false — the use of data required is too scary and people do not want or need it — but that is why it is important to understand and address the concerns we can if societies are to navigate towards the farmland.
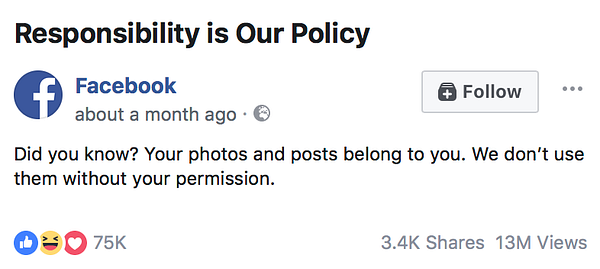
It told me that my “photos and posts” belong to me and that “[Facebook] won’t use them without [my] permission”.
The same advert has appeared in the feed of friends and work colleagues based in the UK. It seems to be part of a campaign. Perhaps the campaign is related to the imminent European Union’s General Data Protection Regulation and the growing public awareness that there is debate around data, how it is used, and whether to trust those uses.
“You own all of the content and information you post on Facebook, and you can control how it is shared through your privacy and application settings”.
Both messages are simplistic, at best. I don’t fully own or control the content I post on Facebook. It doesn’t only belong to or affect me. By over-simplifying its messaging Facebook, like many other organisations, is missing the chance to help explain how its services work and help us all make better decisions when sharing content.
Social media content is more complex than you might think
This will sound counter-intuitive to many. I mean shouldn’t I have control over my data on Facebook? It’s about me! I created it!!
These people are not my friends. They are from a film called Peter’s Friends. But it shows some people in a picture they may regret in later life.
My list of friends is a list of relationships with other people, people tag someone in a post saying that they went to a restaurant or pub with them, or share a picture or comment about a group of friends.
Most of us will think about our friend’s feelings when sharing content about them on social media, but we don’t always know what will be important to them. The rules aren’t written down. Many of us will have had the experience of sharing something and then having a friend say “hi, do you mind deleting that post because of X…”.
Sometimes we listen to those objections and sometimes we don’t. Our friends might not be able to delete our Facebook content without our consent but their views are part of the complex set of things we think about when posting. They can unfriend us in real-life as well as on social media.
Adverse impact on other people
Beyond affecting a personal relationship there are many types of adverse impact that a Facebook post might have. Affecting copyright owners is one. Copyright has manymanyflaws but it is one of the ways societies help creators benefit from their work.
If I did own all the content I posted on Facebook then presumably I could post a picture created by someone else and start to make money off it by selling things. Money that could have gone to the artist.
I could, but I shouldn’t.
Both Facebook and I recognise that we need to abide by copyright legislation and that governments help enforce it. A copyright holder can complain directly to Facebook, or through the relevant national or international rules. The content is not mine to own to control and use how I wish. If I breach copyright in a way that unfairly impacts creators then fewer nice things get created. That would be bad.
Germany recently passed a new law stating that social media platforms have to take down hate speech within 1–7 days or face large fines.
Going deeper into adverse impact it could be that someone on Facebook posts something with the intent of causing harm.
Facebook is a global service, and the legislation and definitions of those things will change from country to country, but in many countries those things would be illegal. A poster would lose control of the content, and perhaps even their liberty, as democratic governments use the powers given to them by people to stop the content from being seen and shared.
Facebook has its own moderation rules and tools that allow Facebook’s moderators to intervene proactively or for people to report content and get it removed. Again, that removal can happen without the poster’s consent. The poster is not in control.
Not all of the adverse impacts that moderation rules try to prevent are illegal and intentional. Others are unethical, or against social norms for a particular community or society. Moderation exists because the adverse impact from my posts might damage the health and goals of a community.
Moderation is not only done by Facebook and governments. Many community groups within Facebook have their own moderators and policies. Group moderators can also remove content without a poster’s consent.
Perhaps the moderators of sassy socialist memes or sassy libertarian memes will remove content I post in their groups if my content just ain’t sassy enough. The local Facebook group for the town I live in, like many other local Facebook groups, certainly has a fierce response to excessive advertising or outsiders criticising the town.
Other people can benefit from content
Shifting to a more positive, and less sassy, note people should also be aware of other people who can benefit from content they post. As the Financial Times recently noted “an explosion of [trustworthy data, such as that posted on Facebook] would give us the capability to understand our world in far more detail than ever before”. Facebook shares some of the data you post already so that other people can benefit, I think it should do more.
OpenStreetMap’s data is freely available as open data and used by governments, businesses, communities and indivudals all over the world.
For example, Facebook users help maintain data about things like cafes, restaurants and leisure centres. We don’t only need this type of data in Facebook, we need it in many other parts of our lives, so Facebook have been exploring how to share data with the community-maintained OpenStreetMap. That will help everyone using the thousands of services that use OpenStreetMap. The Facebook users are not in control of this flow of data but they, and many other people, will benefit.
In other sectors rather than downloading data I can give a third party that I trust the right to access it
In other contexts then Facebook users might want to share content that they post with a third party that they trust.
I might decide to do this so that it benefits my local community, for example helping local government understand feelings on a particular topic, to help deliver another service I want to receive, for example by asking my friends if they want to join me on a a new photo-sharing service, or to help me learn things about my own behaviour and habits.
Unfortunately despite Facebook telling me that I can control how data is shared I can’t easily share that data with third parties.
Facebook allows people to download data they post, but it is not in a standard format and I can’t simply give another organisation that I trust the right to access it to the same extent that, say, the UK banking sector is starting to do.
The UK’s banking sector is expecting to see increased competition and new services as a result of making it easier for people to share data. Perhaps social media firms and the people who use their services would benefit from a similar collaborative effort to determine how to safely share data, which mostly includes other people, without creating adverse impacts.
It is good that Facebook is starting to share data to create benefits outside of their own service. They should do more of it by sharing carefully anonymised data openly, more sensitive data in secure conditions with researchers working for the public good, and by giving people ways to safely share data that they post with third parties that they trust.
Explaining this stuff is hard, but it is necessary
This stuff is complex and can be hard to explain in an accessible way, but it is necessary to understand the complexity before trying to make it simple.
Like many other types of content and data, Facebook posts and photos can be about more than one person. The content can create adverse impacts for those other people but it can also create benefits too. Because of this, users are not fully in control of the content they post, and they certainly don’t own it in the same way that we might own a house or car. Instead civil society, governments and service providers need to work together to design ways to help give people more control and to maximise the social and economic benefits, while minimising the adverse impacts.
Over-simplifying this necessary complexity risks us slipping into a world where instead individuals fully control the data that they create. That is the world that Facebook’s ad is describing to many people. How silly. That world will reduce the benefits and increase the risk of harms.
We don’t need more lengthy and unreadable terms and conditions but as the debate over data grows it would be helpful if major service providers like Facebook took greater responsibility in helping to create a more informed debate and helping people to make better decisions.
Approximate words of the talk I gave at the EU datathon in November 2017.
Hi, I’m from the Open Data Institute, or ODI. I’ve been asked to do a quick talk before the next panel about “open data and advocacy”. I’ll keep it quick so you can get to the panel and the Q&A. Asking questions is much more fun than listening to a presentation 🙂
We’re a not-for-profit. We work globally, our headquarters are in the UK. We were founded 5 years ago by Sir Tim Berners-Lee, the inventor of the web, and Sir Nigel Shadbolt, an AI pioneer. Our mission is knowledge for everyone.
As you might have seen on the first slide it’s our 5th birthday this year. Yay us. So, I want to share a bit about what we’ve learned about advocacy and open data in that time.
First, let’s talk about open data. Open data is vital and incredibly important but if we only talk about and use open data then we can’t deliver our mission. Instead we work across the data spectrum.
The data spectrum is about access. Who can get to data so they can use it or share it or etcetera. Some data should be kept closed within an organisation, like sales reports. Other data should be shared: the police need to be able to see your driving licence, medical records can help with research, twitter data can help us understand how social media is impacting our societies. Lots of data should be open like bus timetables, maps and addresses.
We need to talk about and use the full spectrum of data if we were to get more open data made available so that anyone can access, use and share it.
The second lesson is about goals. Sometimes it can feel to other people like the goal of the open data movement is only to publish more open data or to put data on portals. That’s the wrong goal.
We think, talk about and use open data as a tool.
A tool that we use to solve problems. Like finding a job that you enjoy, combatting corruption, finding your way around a city, responding to the threat of anti-microbial resistance, helping with house planning and building, or understanding the growth of new sectors and business models like the sharing economy (something we’re looking at in our new R&D programme).
The third lesson is about chance. Chance is great. Very unexpected things happen when you open up data. One of my personal favourites is that the UK government opened up radar data that was originally gathered for planning flood defences and people used it to discover both new places to grow wine and new Roman roads that criss-cross parts of the country. Fantastic. But that doesn’t always work.
We need more focus on creating impact by design. Looking for problems, working with people who are experts in tackling it and getting them the data they need. To move data to the right place on the spectrum. When we do that then chance can also happen, but we also have a much higher chance of impact.
We also learnt that we need to combat the very strange view that data is oil or coal or other types of fossil fuels. I can talk in economic theory about the different qualities of data and oil, but there’s a more important difference. It creates the wrong mentality. People fight over control of oil. They want to hoard it for themselves. They want to sell it for huge amounts of money.
Instead we need to turn data into infrastructure. It is already heading in that direction but we need to strengthen that momentum. Great infrastructure is boring, reliable and safe to use. It’s there when we need it. Data is decades away from being boring, trust me *pause for ironic, self-knowing laughter*, but that’s the direction to head in. Turning data from the public and private sectors into infrastructure that underpins every sector of our economy and societies.
And that infrastructure will be built on a foundation of datasets that are made available as open data, for anyone to access, use and share. That foundation of open data makes it easier to publish and use other data. It’s a powerful way of thinking.
So those lessons are some of the ways we learnt to think — about the full spectrum of data, about data as a tool, about impact by design, and about data as infrastructure. Those mental models have helped our advocacy.
But over the last five years we have also learnt some methods that work to create impact.
We’ve been working with whole sectors to help them use data.
The UK retail banking sector is opening up data about products, locations and cash machines and creating open APIs so that people can choose to share data held about them by banks with people that they trust. We hope it will make it easier for more people to create better services for bank customers. We’re talking to other countries on multiple continents about helping them to make the same change. GODAN (the Global Open Data for Agriculture & Nutrition) initiative that we work with is working globally to open agriculture data to solve problems.
OpenActive is opening up sport data to make people more physically active. Places that offer a whole range of sports: football, squash, badminton, table tennis, running are opening up data and they’re also building an ecosystem of organisations that will use that data to make it easier for more people to play the sports they love.
There are more sectors, like transport, coming together as they start to see the power of working together to solve common problems. We need to encourage sectors to understand and unlock the value of open data by focussing on infrastructure, skills and open innovation.
We’re launching a report next week on the grocery retail sector and GDPR based on consumer research, sector interviews and our thinking about sectors. We want to encourage the retail sector to work together to focus on opportunities, and to use the data they hold in ways that builds trust in shoppers and gives them better services.
As well as sector programmes we work on practical advocacy. Here’s two examples.
A data ethics canvas to help organisations using data understand, openly debate and decide on ethical issues about collecting, sharing and using data. Interestingly when we looked at data ethics we found that most of the debate was about personal data in the closed and shared parts of the data spectrum. People had missed the ethical issues around open data.
We’ve also been working on networks. Peer networks are horizontal organisational structures with members who share similar identities, circumstances or contexts. We run global, African and European peer networks for open data and have seen their power in developing learnings and creating change. We’re learnt from how they have grown and how the people in them interact.
We’ve been seeing peer networks start to emerge in other work they do. Things like ODINE (open data incubator Europe), Datapitch (another Europe-wide startup incubator), and the sector programmes.
We believe that fostering other peer networks: in sectors, in particular disciplines (like policy), or in particular geographies will help build a better future faster. We’ve published a method report that we, or others, can use to do that.
Oh and finally, there’s another vital method. Having fun. Sometimes it can feel like things are moving slowly or in a bad direction and that things will never get better. But just as open is a political statement, we should also be aware that optimism is a political act. Having fun helps me be optimistic. Choosing to be optimistic both helps the day go faster and helps create a better future.
Thank you. I hope this talk and the rest of the event is both fun and useful.
As I’ve been starting to get to grips with technology policy over the last few years one of the things that has fascinated me is how little reference to history there is. When I read historical books and talk to people about technology and innovation history I find some frequent gaps. We need to learn from history if we are to make the best of the opportunity created by the current waves of innovation and technology.
For example, people talking about the wonders of technology talk about how few staff WhatsApp had when they were bought by Facebook, yet don’t talk about how few people sailed in the Niña, the Pinta, and the Santa Maria when Columbus sailed across the Atlantic. After Columbus’ expedition more and more people crossed the Atlantic, for exploration, for business and for pleasure.
WhatsApp’s success built on the internet, the web, cryptography and smartphones. Similarly Columbus relied on inventions in navigation and shipbuilding. Neither could have achieved what they did without those previous inventions. Are they analogous?
Learning lessons from history
Recently I read a couple of books that helped me sort out some of my thinking about lessons from previous waves of technology-driven change. The books were Ruling The Waves by Deborah L. Spar and The Master Switch by Tim Wu. They are good books. If you’re interested in technology policy you should read them too. I’ll lend you my copies if you want.
Ruling The Waves uses ocean sailing, telegraph, radio, satellite television, cryptography, personal computer operating systems and digital music to explore innovation. It proposes that they show four common phases: innovation, commercialisation, creative anarchy and rules. Different actors dominate in each those phases.
There are piratical adventures in the early years before the surviving, and now dominant, winners encourage government to work with them to bring order to the new technology. Using the model of this book would show that my silly Whatsapp/Columbus analogy is fatally flawed. Columbus was in the innovation phase, Whatsapp (and other messaging services) are in either the creative anarchy or rules phase. They’re very different kinds of innovators.
Ruling the Waves argues that the eventual rules tend to be dominated by intellectual and property rights. It shows that it can take decades, or even centuries, from innovation until stable rules are in place.
The Master Switch looks at lessons from the telephone, radio, broadcast and cable television, and Apple to propose that all information technologies go through a cycle of decentralisation to centralisation ending with a corporate (or state) monopoly where innovation, the economy and consumers suffer.
It argues that a separation principle can help prevent this fate.
This principle would keep a distance between young industries and existing monopolies to enable new technologies to show their worth; between different markets to make it harder for monopolies to spread; and between the public and private sectors to prevent government from favouring friendly monopolies.
After reading the books I was more convinced than ever that the waves of change bought about by the internet and web will take decades, if not centuries, to be absorbed into our societies. It is seductive but false to think that we can legislate for technology and data quickly. We have to allow for experiments to learn the right legislative and regulatory frameworks.
Gaps in the lessons
But there were gaps in the books. That’s not unique. I see the same gaps in lots of technology policy and thinking.
Despite the best efforts of Victorian inventors the vast majority of dinner tables do not yet feature a minature railway delivering food to bearded men. Picture from Victorian Inventions by Leonard de Vries
Major enabling waves of technology like the internet and web underpin lots of other innovation — like smartphones, social media and search engines—that each have their own journeys to go through. Some of these smaller waves will have lasting impact, some may disappear and get washed away, others are badly timed and will come back in a while. But the waves don’t stop. They are continuous. That is one of the reasons why open culture is so important. It keeps us open to innovation, new ideas and challenges from outside of a small circle of friends and organisations.
Both books miss the impact of data in the current period of change and that much of this data is personal data. It is data about you, me and billions of other people. Most data is about interactions between people, or between people and organisations staffed by other people. It is difficult, if not impossible, to determine who ‘owns’ data. For most data there will be multiple people and organisations who have rights. This makes it hard to rely on property rights as a way to shape and bring rules to the market. The challenge of building good governance for data infrastructure will need a more systemic response than property rights.
The books also focus on the US and UK, with some excursions into mainland Europe. While they describe the differences between European and US approaches to regulation, with Europe typically intervening more, I would love to see more about the lessons learned by other countries. The web, the internet and data infrastructure cross, and therefore soften, national boundaries. Learning from and listening to other countries and societies will become even more important as these waves of technology reach their full power. These excellent recent reports from the Web Foundation are useful for those in a US/UK filter bubble who want to start listening more widely.
Innovation has limits
And finally both books miss the influence of societies and people. They are books about economy, regulation and business. They miss the social side of the change.
Lots of the impact of technology is societal as well as economic. Similarly the forces that impact on and affect technology change are both societal and economic. People adapt to technology and innovation, but sometimes they push back and reject it. Those rejections can be learned from.
The innovations that led to Christopher Columbus crossing the Atlantic also led to industrialised slavery. Slavery might have helped create the modern world but it is an evil that should not have happened and should not still be happening. We could have intervened earlier and stronger to stop it. A modern world similar, but not the same as, our current one would still have been built. It would have taken longer but it would have damaged billions fewer people in the process. Our societal norms now reject slavery and many of the other things that that particular innovation enabled.
As our societies matured we embedded some of those societal norms and values into legislation. Human rights, worker’s rights, anti-discrimination, health and safety, and data protection are some obvious examples. They are strong signals from society indicating where innovation is encouraged and where it isn’t.
The precise rules will vary by country but while the boundaries of legislation will contain things that need to adapt as we learn how to do things better at the core of the legislation are societal norms and values. We cannot and should not forget our values as we go through this wave of change. Those values do change but that change should be vigorously and openly debated.
Innovation can take strange paths and be used for unintended purposes. We need to engage and work openly with societies and people if we are to both understand the limits and share the benefits of the current waves of technology.
What does this have to do with my job?
Over the last couple of years I’ve been working at the Open Data Institute where I spend about 50% of my time working with the private and public sectors delivering projects and building services. We help businesses and governments understand and adapt to the wave of change being bought about by data. The other 50% of my time is spent developing our policy thinking based on what I and the rest of the team and network learnt from delivery and research.
Clearly data is not “good” infrastructure right now, too many people can’t get the data that they need, so we think a lot about how governments and businesses can help strengthen it. We look at history when we do that. This is all part of my research. How did we recognise things becoming infrastructure in the past? How did we learn how to design and build good infrastructure? How long did it take? Do historical examples contain useful lessons?
What should I read next?
Anyway, like all of my blogs, I’m thinking out loud. These are some of the things my recent work and reading about history has made me think about. The gaps in the last two books led me to pick a book on the anthropology of roads as my next one. What should I read or who should I talk to after that?
In my job at the Open Data Institute I sometimes talk with people, from businesses and governments, about how better use of data can help them design and deliver better services. I’ve been using a public sector example recently that I’ve not written down. Here it is.
Ways to get bus timetable data to people who need it
The example I use is bus timetables. People need to know the times and routes of buses so they can make a journey and get to their destination. When I use the example I talk through four of the patterns that can be seen in many cities and towns around the world for services that get bus timetable data to people who need it.
Mass market private sector services: many cities and towns now have bus timetables available as open data. Private sector services like Google Maps, Apple Maps and CityMapper pick up this data and build it into a service which they aim at the mass market of smartphone users. The services work in many cities and might haveother features such as information about restaurants and pubs. They get their open bus timetable data either directly or through a data aggregator, like TransportAPI or ITOWorld, who collate data from multiple cities / transport providers. That takes aways some of the effort from using open data and makes it easier for more people to build services.
Targeted private/public sector services: smart cities and towns recognise that the mass market services don’t always meet all needs, particularly accessibility. If you look closely you can often find small bits of public services meeting the needs of some users, or a transport authority running a challenge to help focus the private sector market on meeting particular user needs. Left to its own devices the private sector might only target the profitable and easy-to-serve mass market, a challenge can help change that to build more accessible services or to experiment with new technologies like AI or voice interfaces. Targeted services often use the same data aggregators as the mass market services. It’s the same data, just presented for a different set of user needs.
3. LocalBusTimes: a local website and/or smartphone app where people can look up the timetables for a journey they want to make. It might be for a whole town or a single bus company. It probably started by only providing bus timetable data, nowadays I think more of them recommend a route. The local authority or bus company typically run the LocalBusTimes service themselves.
4. Physical services: not everyone has or uses a smartphone when they need bus timetable data. There are many reasons for this. To give just a few: there might be no coverage, they might not be able to afford a smartphone, they might have run out of credit/data, they might not want a smartphone, their city might not have made bus timetable data available or they might simply have run out of battery. That’s why bus stations have information desks, why bus stops have timetables printed and stuck to them and why people ask other people “when’s the next bus?” on the street. Someone has used the bus timetable data as part of the design for the bus stop or as part of designing an operational process to help a human answer another human’s questions.
Some of the reactions I get to my example
No one, yet…, has told me that my example is stupid or dull. Feel free to be first to do that.
When I talk through this example with people the usual reaction is that while lots of people knew about the transport sector and data few people had thought of all the patterns or wondered about how they could be applied to their work in another sector.
Most people had used the mass market services but very few people had thought of using the market, in this case through open data and challenges, to help them meet their own goals. Those that had thought that they risked losing control to the market and hadn’t realised that they could still discover if user needs were being met — for example through user research — and could use a variety of ways to shape the market to target unmet needs. Challenges are just one of the ways to do that. Governments can legislate. Both businesses and governments can use procurement, strike deals, make different types of data more open, either fully open or in a more controlled way through APIs, or lots of other forms of soft power to shape the market around them.
I also find that few people had thought of the physical services pattern as part of the overall service. I find that sad. It also shows that I’m in a bit of a bubble and exposed to only some views. The tech world is overly focussed on services that end in smartphones and websites. I expect/hope that’s a passing phase.
Why I’m writing this down now
I’m writing this down now because I’ve been using the example for a while. It’s good to publish it to get my thinking straight, to show some of the reactions I get and to learn from new reactions. As I often say, data is becoming infrastructure that will be as open as possible. Businesses and governemnts need to adapt to that future. They have different goals, and needs for democratic accountability, but can learn from and collaborate with each other. I’m expecting to do some more work on public sector service delivery models over the next few months. It’s good to share, even shoddy, thinking early. It’ll help make that work better.
Warning: this post contains content that will be offensive to some people.
The post is a version of talk I gave at the ODIFridays series of lectures at the HQ of the Open Data Institute in London. The slides and a video of the talk are at the end of the post. Like most of my talks I adlibbed a bit. The post has links to most of the material I adlibbed from, others are at the end of the slides. It includes some thoughts on swearwords, Roger Mellie, democracy, censorship, Blackpool FC, artificial intelligence, context and an apology to my mum.
One of the UK’s regulators, Ofcom, commissioned research on offensive language last year. The research got lots of headlines. It was a nice opportunity for papers and websites to make cheap gags about swear words.
But it also gave me an opportunity to open up some swear word data and to use that example to talk with people and think about things like democracy, censorship, context and artificial intelligence. I made some cheap gags about swear words too.
After some discussion within the ODI and with Ofcom’s research team we ended up with this. The same data as the PDF but in a format that is both human and machine readable.
Now, a big part of our job at the Open Data Institute is “getting data to people who need it”. Normally I start with problems but this time I had started with data. My bad. Now to find out who needed it and how they would use it.
Some of the things people use this swear word data for
As I put the data out on twitter there was a background mantra of “arse…balls….knob…bastard…” from around the office. One person then wrote a little script that people could use to get their computers to say the list of words. Soon I could hear both human and machine voices swearing away. The swearing mantra was charming, if a little unsettling, but I had my serious face on. Why do people swear?
The main purpose of swearing is to express emotions, especially anger and frustration.
Seems fair. I suspect that a lot of people get frustrated at not being able to get data they need to do something. That explained the background mantra from the Open Data Institute office, but what about other uses of the data?
Roger Mellie, copyright Viz. Note that the swear word data might allow people to block his language, but not his gestures.
The content of the report told us about some other users. It would help TV broadcasters and presenters understand how people would react to things that they said on air and so help the presenters decide what they could say.
For example the word “bollocks” was seen as somewhat vulgar if it referred to testicles but less problematic if it was being used to call something ‘nonsense’.
This might mean that people did or did not say words in certain contexts. It might lead to some content only being accessible if a PIN was entered to unlock it.
We have given Ofcom the power to fine organisations and people that breach their codes. By publishing the report openly, they were helping broadcasters understand how they might use those powers and therefore discouraging breaches. This probably makes the system cheaper and more effective.
Broadcasters are likely to have their own guidance to help them meet the expectations of their target audiences. They could merge Ofcom’s list with their own list to help them meet both society’s needs and their own user’s needs.
Similar data is maintained in contexts outside of TV and radio
In Britain Mary Whitehouse was a famous campaigner from the 1960s to the 1980s against things that she found offensive. I can imagine Mary being keen on data-driven censorship. Image fair use via Wikipedia.
The data includes the word ginger saying it is ‘mild language, generally of little concern’, but the word ginger can also be used to describe a very tasty type of biscuit. A filter that used the swear word data to block offensive words might ban ginger nuts. That would be bad. This is a common problem with simple data-driven solutions. They ignore context.
I couldn’t find a list of offensive biscuit names but there are other sets that are similar to the swear word data used in contexts other than TV and radio.
The UK has a list of suppressed car registration plates
It is the job of part of the UK government, the DVLA, to maintain a list of combinations of letters and numbers that you cannot put on a car. Unfortunately, and curiously, the list is not published openly, but sometimes it is made available after freedom of information requests.
An extract from the suppressed car registration plate list via Whatdotheyknow
The list of suppressed car registration plates helps prevent confusion over typographically similar symbols, like o (zero) and 0 (oh). It blocks language that is likely to be considered offensive, for example “*B** UMS” and “*R**APE**”.
The list also explicitly contains the names of terrorist groups such as the UVF, UDA and UFF. Another terrorist organisation, the IRA, are already banned, like any other organisation beginning with I, because of the potential for confusion between 1 (one) and I (aye).
More controversially the acronym for the far-right British National Party, BNP, is also on the list. The BNP are allowed to stand in the UK’s democratic election process. How was that decision made? Unfortunately just as the list isn’t publicly available neither is the methodology.
Context affects what words are offensive
The UK’s democratic processes produce others lists of offensive words.
The speaker in the UK’s parliament can request that politicians withdraw words when debating with their opponents, so called unparliamentary language. The way in which words are deemed to be unparliamentary or not are unclear. In 2015 the opposition leader Ed Milliband was allowed to call the then Prime Minister David Cameron “dodgy”, yet in 2016 an opposition backbencher Dennis Skinner was asked to leave a debate because he called David Cameron “dodgy Dave”. The word “dodgy” isn’t on Ofcom’s list, it’s offensive to call an MP “dodgy” in a parliamentary debate but not to call them it on television.
The word “Oyston” is offensive to me and my community of fans of Blackpool football club. The offensiveness is not only because of this cringeworthy picture but because of how the Oyston family treats fans.
Another example of offensive language in a particular context is the word “Oyston”.
The Oyston family own the football club that I support, Blackpool FC. Because of their actions against fans being called an Oyston fan on one of the websites used by Blackpool fans would be offensive. How would anyone outside of the community of Blackpool fans discover this?
There are related examples that may help us understand how we could do this.
Collaborative maintenance of data
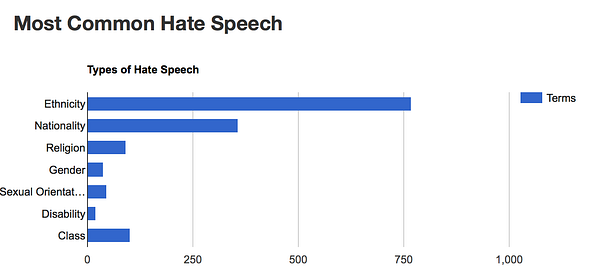
Hatebase maintains a list of hate speech from around the world. The data is maintained by automated processes and manual interaction to cater for how hate speech changes over time and in different places. Hate speech can be used to encourage violence against people and communities. The collaborative maintenance process allows people to debate which words are hate speech or not.
Other people could learn from the example of Hatebase. If British politicians wanted, and could get to grips with github, then they could collaboratively maintain my initial list of unparliamentary language and create something that would help them understand the boundaries of offensiveness.
Offensiveness is affected by time, place and communities
By this point in my own research I was clear that the context of offensiveness is affected by time, place and communities.
When I checked I found that swearing philosophers were, of course, already aware of this. As often happens I was a technologist rediscovering ground that others had already covered. But technology can also affect how and which words become offensive.
People create new offensive words
Oyston is an example of a word that became offensive to a small group of people before becoming offensive to a larger group. Blackpool fans have effectively used social media and the press — oh, and talks & blogposts like this ;) — as part of a campaign to get the Oyston family out of our football club. An effect of this has been to spread the understanding of the offensiveness of the Oystons from the seaside to wider parts of the footballing community. A more famous example is the case of Rick Santorum who found his surname defined as an offensive word in a campaign led by Dan Savage.
This is a challenge to any list of swear words and a risk for people who use them. People create new offensive words for their own purposes. They game systems.
Would people game the swear word data I created from Ofcom’s list? Yes, of course they would.
An example quickly came to mind. When I published the Ofcom offensive word list as open data then in line with good practice I gave every entry a universally unique identifier (UUID). UUIDs make it easier for machines to use the data.
If this data was to get widely used then how long would it be before people started to circumvent the system by being interviewed on telly wearing t-shirts with the UUID of a swear word? Perhaps over time the UUIDs, or parts of them, would become offensive? “That fella’s a right 81cb.“, they’d say. Maybe the UUIDs would need to be added to the list as they became offensive?
People adapt and change. That is one of the best things about people and one of the biggest challenges we face when maintaining and using data. We need to build in mechanisms to change datasets over time as needs and uses change.
Swear words-as-a-service is hard
It is clear that swear word data was easy to build and also clear that it would be more difficult to maintain and make it useful in multiple contexts.
I knew that many companies were already maintaining similar lists as, like many other people, I had seen, laughed and evaded filters on websites that had turned the British town of Scunthorpe into the apparently inoffensive “S***horpe” due to simplistic and bad data-driven algorithms. I do wonder how useful those filters and services are.
Many of the website filters I had seen are simple and flawed because of the lack of context and their inability to adapt to people’s changing behaviour but thinking ahead I wondered if people would start to apply machine learning / artificial intelligence (ML/AI) and create services that could automatically learn new swear words? Perhaps this could be used on a massive scale to reduce the damage caused by offensive language on the web?
I knew that I wouldn’t be the first person to think of this idea. While 2016 had been the year when every problem could be fixed with a blockchain, 2017 is the year of ML/AI.
A quick search of patent libraries showed that in 2015 Google had registered a patent to classify offensive words using machine learning. Unfortunately it looks rubbish. The training mechanism worked on a large set of text samples, it failed to recognise the context in which the text was being used. The resulting service might be slightly better than current filters but would still be data-driven rather than informed by data.
Maybe, like Hatebase, it would help if users were to train the machines that provided the service. After all Google, like most other large internet companies, use thousands of people — including you — to help train their services. I started to consider what I had learn about offensive language and think of the tasks that Google would need to give to swear word raters to train their machine:
Task: go to a football ground in Gdansk, Poland. Play this video to people near you. Observe their attitude to you, and each other, over the following seven days and then categorise the offensiveness of the video. Repeat this exercise every 3 months.
Hmm… I quickly realised that this might be a Quixotic mission and that AI/ML might provide a better service but still only a partial one. There would be no perfect service. People decide what is offensive, not machines. If the service only considered some contexts then the people who controlled the machines and trained them on those contexts would be the ones who decided where it was useful. Swear word data isn’t like the location of bus stops or the list of transactions in a bank account. The context is even more important.
This is one of the challenges of the web and providing data and services for it. The web is pervasive. It interacts with the physical world in many places. It appears in multiple contexts. I use the web to watch broadcast news, like that regulated by Ofcom. I use it keep up to date on politics, where the unparliamentary rules are useful. I talk about football, and the Oystons, on message boards. I keep up to date on current affairs, and feel helpless at the levels of hate speech deployed at people in the UK and abroad. I chat to friends, both publicly on sites like Twitter and Facebook and also privately in messaging applications.
Datasets and services that reduce offensive content on the web will need to cater for all of these different contexts, and more. Even if they do, some people will still work around them. Data and technology may be able to help the problem but it will only ever be part of a solution to something that is fundamentally a more human problem. Our need to express our emotions in language.
Sorry mum
It was clear from my investigations that we could usefully create data about swear words, i.e. words that are offensive. That the need for this data came from people who swear, people who didn’t want to swear and societies & communities trying to decide the boundaries between what was offensive or not. That it would be useful if the research and rules for deciding on what was offensive were open. And that if people could collaborate to decide on what was offensive that the data would be more useful because it would cater for more contexts. But it was also clear that while technology creates new possibilities to reduce offensiveness that people will still adapt to achieve the goal they want. So it goes.
The other thing that was clear from the talk was mine and my audience’s squeamishness with some of the words. In my case it was certainly because of one of my most important contexts: my upbringing and my family. I’d like to end this post the same way I ended the talk by apologising to my mum. Sorry mum.
The questions from the audience showed the importance of context
At the end of the talk at the ODI the audience raised several points about offensive language that had not been covered in the talk, such as the use of racial and religious slurs. I was already covering a wide topic. Racial and religious offensiveness cover even more ground. I couldn’t cover everything.
Image from The Wanderers, based on a book by Richard Price. The film includes a fantastic scene in a 1960s New York school where people of different religions and ethnicity try, and fail, to remember all of the offensive names they have for each other.
I did find it interesting that the audience in the room hadn’t heard of some of the words in the list. Particularly choc ice, blood claat and bum claat, words that in my — white, middle class, mostly Northern England and South London experience — are used against black people or in black communities. In the case of the latter two more specifically within Jamaican communities.
That people hadn’t heard of these words says something about the context of the audience. A context where those words may not have been seen as offensive. Perhaps next time I talk on this topic I should try and sneak in some offensive language from different contexts to see what happens.
Watch the original talk or read the slides
If you want you can watch a recording of the talk (which includes some swear-a-long fun):
I occasionally walk around, wave my arms and proclaim:
data is infrastructure, just like roads
I alternately blame and praise the brilliant Jeni Tennison for this strange affliction. I praise Jeni for coming up with the wonderful analogy of roads for data, I blame her for infecting me with the bug of excitedly talking about it to anybody and everybody so that I can learn from what they think.
I recently proclaimed that data was like roads to a friend who has a degree in classics and spent a career teaching in primary schools. She is very well-read.
My friend asked me if I thought that as a society we were well advanced in building our data infrastructure.
No, I said, it’s only been a few decades since the invention of the internet / web which led to the current massive growth in data, I suspect it will take a decade or two before we learn how to do data things well.
I think you’re right, she replied, after all the data infrastructure that you describe sounds a lot like the Roman roads and it took us a couple of millennia to start getting roads right.
Really? I said. Roman roads? That sounds interesting….
Roman roads were for the economy as well as the military
Our usual vision of a Roman road is either a muddy field being dug up by a team of archaeologists or an army of Roman soldiers marching to try and conquer a new land. But Roman roads were used by other people too. They were an important component of the Roman economy.
People transported goods along them for trade and materials for building new houses. Books have been written about the impact of roads on Roman Egypt and Italy — they had sophisticated pricing models, integrated their road with other modes of transport and they evolved governance arrangements to manage the development of their roads.
But Roman roads were not only for armies and traders. They were also used to transport messages, taxes and people. Along the cursus publicus, or public way, there were mansios, or waystations.
A first edition of the first UK Highway Code by Mikey Ashworth, CC-BY-2.0
The analogy of roads helps break people out of the usual mindset when thinking about data. The frequent comparison with oil is particularly misplaced.
The analogy of roads is much more relevant. The importance of maintenance;the need for big, open roads between large towns and the value of smaller roads for villages; the dangers of toll roads and expensive or complicated licensing; and rulebooks for how to use the roads.
It’s a pretty decent analogy, as analogies go, but my friend had started talking about Roman roads.
Roman roads helped co-opt other economies
Mansio were set up along the roads. They were maintained by the Roman government and used by officials and armies. Officials from the government and their animals could sleep, get washed and get fed. Many other people could use the mansios too but they would have to pay for the privilege.
The money people paid would go to the upkeep of the mansios and to the running of the cursus publicus. The cursus publicus was a transportation system, both for people and for messages. Officials and their information would travel for free. Everyone else would have to pay. It was a massive toll road network set up across a range of nations with preferential access for one group of people.
Other people would pay because the Roman roads were so much better than the roads they could build themselves. There was no real competition: if you wanted to go from A to B you had to go Roman. As a result many of the mansio gradually grew into towns.
A Roman coin showing Marcus Aurelius. Copyright: CC-BY-SA 3.0 by Rasiel at English Wikipedia
After telling me the tale of Roman roads my friend turned to me and said: isn’t that what you just described? Aren’t Google, Microsoft, Amazon and those big government agencies a modern cursus publicus?
Oh, I said, yes they are.
What have the Romans ever done for us
As I noted earlier “data is roads” is just an analogy and IANARH (I am not a Roman historian) but the similarity of the Roman system to our current data infrastructure was both striking and reassuring.
The Roman road system was striking in its similarities, even down to people bemoaning what the road builders have done while using their roads, recognising that what they’ve done is actually very good and realising that in many cases it couldn’t have happened without them.
It was also reassuring. History is full of repeated patterns and perhaps the current stage of evolution of our data infrastructure is a necessary stage in a pattern that repeats when new infrastructure emerges.
We learnt that roads needed to be run as a system
Roman roads might have started off as a form of military and economic conquest but we gradually learnt more about the need for roads to be run as a system for the good of everyone in society. This took a while, as did our understanding of government’s role in making that happen. The case for this involvement evolved as we understood the decisions that needed to be made.
A thousand years after the fall of the Roman empire the UK decided that governments should take a stronger role in roads with the first Highways Act in the UK. 300 years later the Rebecca Riots against toll roads contributed to the gradual removal of charges and the transfer of responsibility to central and local government for maintaining most roads. Private roads, for example the path to your house or the bit of road to a local factory, were not transferred but governments make sure that we have a duty of care to visitors and workers.
But one final thought. Many of the major roads in European countries are still based on the old Roman ones. I wonder if in 2000 years our data infrastructure will still show signs of its 21st century origins and the decisions of the people who are building it now?
If you enjoyed this story, we recommend reading our latest tech stories and trending tech stories. Until next time, don’t take the realities of the world for granted!
Hello. This is the personal website of Peter K Wells. I do politics, policy and delivery to try to make data and technology benefit everyone. I also do bad jokes and music references.
This website stores cookies on your computer. These cookies are used to provide a more personalized experience and to track your whereabouts around our website in compliance with the European General Data Protection Regulation. If you decide to to opt-out of any future tracking, a cookie will be setup in your browser to remember this choice for one year.