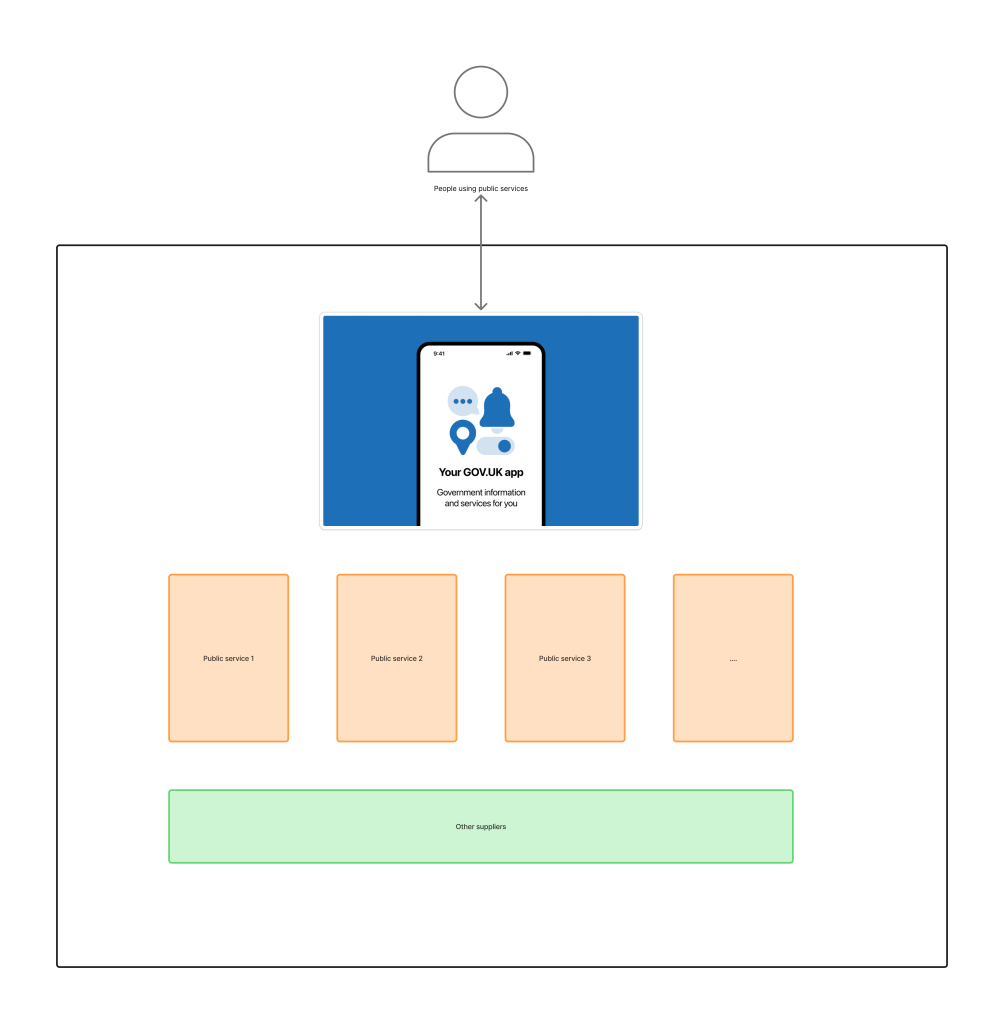
The app is intended to provide another way to access public services alongside other places like job centres, town halls, schools, telephone call centres and the gov.uk website.
Ideally people will be able to choose what route to use based on what works for them, the friends and family they help to access public services, and the particular services they need at the time they need them.
In the circles I work in there’s been lots of discussion of the app
One thing I’ve not seen mentioned is that the app tries to avoid legal responsibility for providing a decent public service to people. It even recommends that people take separate professional advice rather than relying on the services and information provided by the GOV.UK app.
It would improve public services across the sector if the app took more responsibility and encouraged other public services to do the same.
we do not provide any express or implied guarantees, conditions or warranties that the information available via the GOV.UK app will be:
+ suitable for your individual requirements + available + current + accurate
So, the government is unwilling to say that public service information provided by the government is accurate?
We do not publish advice on the GOV.UK app. You should get professional or specialist advice before doing anything on the basis of the content [published on the app].
So, if I used the app to look for government advice on how to get a UK driving licence then I should also speak with a lawyer before applying to the government?
we’re not liable for any loss or damage that may come from using the GOV.UK app. This includes, but is not limited to, the loss of your:
+ income or revenue + salary, benefits or other payments + business ..[there’s more]
So, if I used the app to sort out something to do with my parent’s pension, there was a mistake in the app and my parent lost their pension then the government would not help me or them out?
Seriously?
How do things like this happen?
There’s a few things that could have led to this kind of disclaimer being added to the app. For example:
GDS might worry about taking responsibility for other public sector organisations. Even in its beta stage the app includes bits of public services provided by multiple public sector organisations. Perhaps GDS didn’t want to be held responsible for other organisation’s mistakes? Or even to be responsible for working out who is responsible? But part of the app’s job is to help people understand and deal with the many public sector organisations within it. Not to try to shift responsibility around and leave it to the public to work out how to hold organisations who fail them accountable for those failures.
Traditionally gov.uk has focussed on information. The proposition says that gov.uk does not offer advice on what the user should do, unless users need advice in order to complete their task. The app is due to have a chatbot, called GOV.UK Chat, added to it and chatbots can both add more complex supply chains and provide information in ways that more users will experience as advice. GDS may also be nervous about AI chatbots’ susceptibility to technical malfunctions, like ‘hallucinations’. But, let’s be honest, the point when information becomes advice has never been a clear one and as GDS’s AI playbook says “Ultimately, responsibility for any output or decision made or supported by an AI system always rests with the public organisation”. Sound advice.
When does information become advice?
GDS aren’t used to delivering apps and apps often have terms and conditions. GDS’s One Login app has a similarly strong disclaimer and says there is no liability for “loss or damage arising from an inability to access or use GOV.UK One Login“. Hardly a reassuring statement when millions of people will need to use One Login to get access to things like tax payments, state pensions, disability and unemployment benefits. One Login has already had at least one serious security vulnerability. Who will be liable if, or when, a hacker takes advantage of the next one?
Lawyers gonna be lawyers. It’s easy to imagine some lawyers recommending these kinds of terms and conditions, and people managing the app deciding they need to follow that advice rather than challenge it. If you look then you find that since 2013gov.uk has also had a set of terms and conditions that don’t guarantee the government will provide accurate information and tell people to read the terms and conditions of all the public services they access through gov.uk. It’s important to support people to understand how public services work, but you can’t do that in a set of legal terms and conditions. Yuck.
The app should encourage the public sector to take more responsibility
GDS is not providing a commercial service that can hide behind contracts and lengthy terms and conditions. In the private sector you find backstop compensation schemes – like the Financial Services Compensation Scheme – when organisations fail. There is no equivalent for public services and, to put it politely, the UK government does not have a great record of runningcompensationschemes for its failures.
Instead the backstop for responsibility is ultimately things like administrative law and politics.
Would the app’s Ministers really want to stand up in Parliament and say that the app does not provide accurate information? That people should pay for professional advice after reading advice provided by the government? That the government isn’t liable for its own mistakes?
Not quite the vision being sold by Peter Kyle, and DSIT’s blueprint for a modern government, of more public services that work across institutional boundaries and do the hard work to make things simpler for people.
So, if government lawyers are the ones recommending contractual terms and conditions then both GDS team and its Ministers should say no.
By taking clear, legal responsibility at the app level, and tidying up responsibility on gov.uk too…, GDS can encourage other public sector organisations and their suppliers to take responsibility for providing better public services by making clear their actual legal and democratic responsibilities and ensuring they have clear liability before their services are made available.
The GOV.UK app can shape an ecosystem of other services and suppliers to take responsibility for providing better public services to people.
Given the government’s push on using more automation and technology clear responsibilities and liabilities will only become more important. It might reduce the chance of the government having to create more compensation schemes that can cost billions of pounds.
A culture of responsibility across the public sector would mean that more public services work for people, and fewer public services that fail the people they serve.
When I work within teams, talk with people and read policy and strategy documents, particularly around the UK public sector, I find it useful to quickly align on what people mean by some words so that we can get stuff done. “Digital” is one of those words.
Many words have multiple meanings. Words can gain and lose those meanings over time as us humans do one of our human things and try to communicate concepts to each other.
Originally a Latin word for fingers and toes, “digital” became part of the phrase “digital computer” when electronic computers were invented in the 20th century.
But digital has acquired several more meanings in the last few decades.
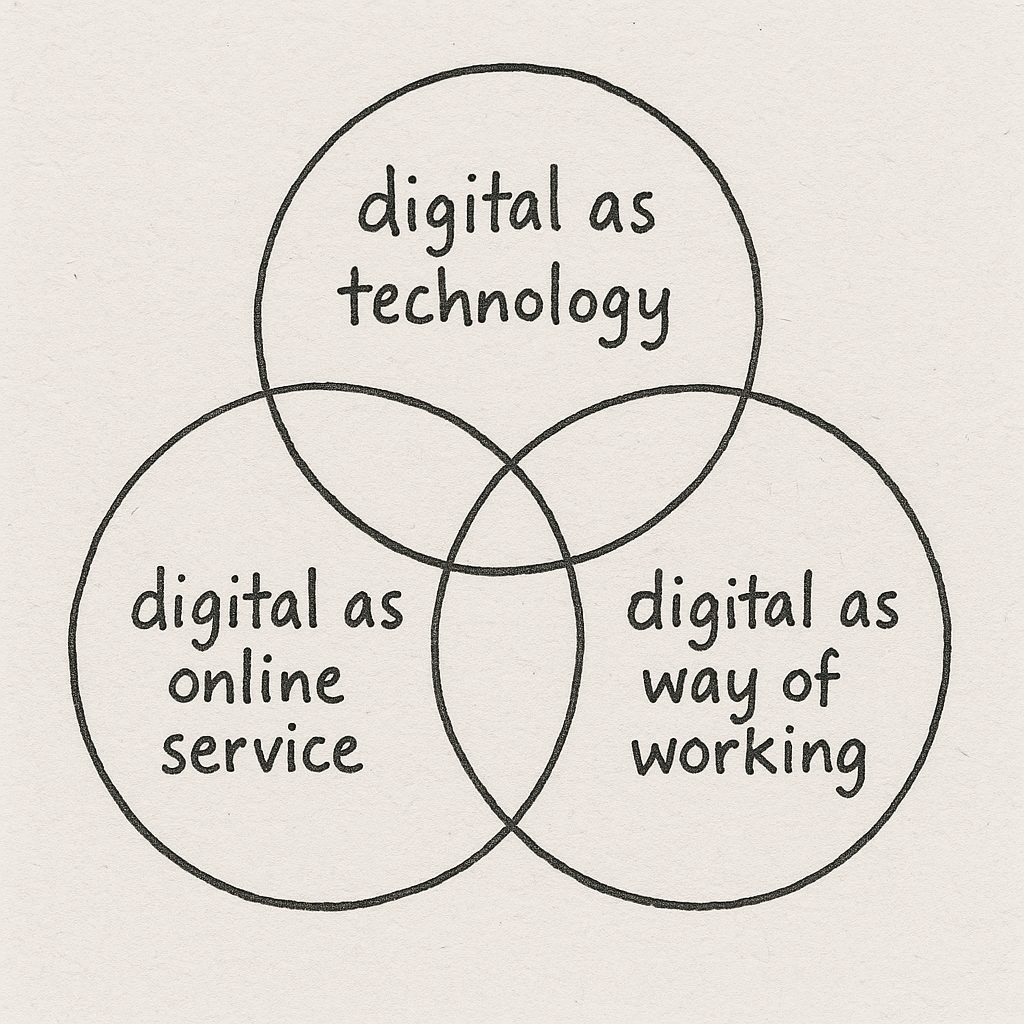
When I ask people what they mean by it there’s different definitions that I regularly hear in the world of digital government policy and public services:
Digital as a type of technology
Digital as an online service
Digital as a way of working
Image drawn by chatGPT as my handwriting is mostly illegible, my drawing is worse and I didn’t want an image that looked too formal. (NB: like most Venn diagrams, the centre is not necessarily a thing to aim for…)
Sometimes these meanings get combined, which can be confusing. I find that disentangling them is useful.
Obviously ‘digital’ is not the only word which gets tangled up in this way, but given its importance it’s a useful one to align on.
1. Digital as a type of technology
Digital can be used to describe any technology related to electronic computers.
This was part of what was happening with the term ‘digital computer’. The original ‘computers’ were humans who added up numbers, it was the addition of technology that made the original computers ‘digital’.
A roomful of human ‘computers’, courtesy of the US Library of Congress. Note how they are all female. Programmed Inequality is a good read on the history of women and digital computers in the UK.
You see this definition used in terms like the ‘digital revolution’ – to indicate the changes happening as the world adapts to computers, internet and the web – or ‘digital infrastructure’ to talk about telecoms infrastructure and data centres.
Implicitly this definition can exclude other forms of technology like physical machinery, roads, wheels, and paper.
2. Digital as an online service
The second usage is digital to mean online services that are only available over the internet or web. It might even be something that only works on a smartphone, like an app. I’m not sure how or why we’ve ended up calling these ‘digital services’ rather than ‘online services’.
Facebook is often called a “digital service” or Google a “digital company”. The UK has a Digital Regulation Cooperation Forum (DRCF) whose purpose is to “deliver a coherent approach to digital regulation for the benefit of people and businesses online” for regulating these kinds of services and companies.
While Facebook/Meta and Google obviously exist in the physical world – just think about one of their many offices, data centres, undersea cables or the tens of thousands of people who work to moderate content – when people talk about their ‘digital services’ they tend to think about the bits that are only visible online.
If you work in similar places to me you don’t need another image of a ‘digital service’, so here’s a GIF of a scary rabbit chasing a cat instead
Similarly the term ‘digital service’ can be used in digital government circles to mean the bits of a public service that are interacted with over the internet and web.
An online service like this is rarely the entirety of a public service – there are many reasons why governments can’t just build websites and apps – but they have become an increasingly important and visible part of public services.
I say rarely, because sometimes governments can reasonably decide that a service will only be accessed online, but there are limits. For example it might be appropriate to require large businesses to pay taxes online but it would be inappropriate to require individuals to pay taxes online unless there was a larger service that provided support to enable everyone to do it.
3. Digital as a way of working
Third, there’s digital as a way of working.
Tom Loosemore of Public Digital talks about digital as ‘applying the culture, processes, business models and technologies of the internet-era’ which is a pretty good description.
No, I’m not going to try and further define digital as a way of working. So, courtesy of Wikimedia, here’s a picture of a roughly organised wall of post-it notes as a way of getting it across.
It emphasises things that are not only technology and indicates that ‘digital as a way of working’ can be used to improve not only ‘digital as online services’ but also a wider set of services and institutions.
Some people take this kind of definition further to talk about who or what ‘digital’ is for. For example Public Digital’s description talks about using digital ways of working “to respond to people’s raised expectations”. I don’t think everyone has raised expectations.
I tend to encourage teams to decide their purpose in their context.
If the context is delivering general public services then the purpose might be “to meet everyone’s needs”, if the context is tackling issues caused by lack of trust then the purpose might be “to deliver trustworthy services”, etcetera, etcetera, etc.
The definitions can get combined
Finally, it’s important to be aware that many people combine the definitions.
Perhaps they’re using digital ways of working and digital technologies to deliver a digital service. Or perhaps it’s a policy or strategy paper where someone has liberally sprinkled the word digital into all sorts of places in the hope it will make the organisation look modern. Perhaps they’ve invented a wholly new definition, *gulp*.
This young man likes digital
Sometimes I even find people that don’t even realise that they’re limiting the potential usefulness of their modern ways of working by only applying it to computer technologies and only to bits of services that are visible online on the web and internet. That they’ve ended up accidentally prioritising a subset of the population and the method they need to use to access public services.
So, separating out the different meanings of the word digital can reduce confusion and enable teams to meet a larger set of needs.
Digital is not the only word that has multiple meanings
And finally. Obviously digital is not the only word that can be loaded with multiple meanings. Just try asking people what they mean by terms like ‘AI’, ‘product”, ‘policy’, ‘personalisation’ or ‘digital identity’ if you really want to have my kind of ‘fun’.
But ‘digital’ is one of the key ones and there’s at least three definitions regularly in use. Understanding what other people mean by it and aligning on a common meaning can be a useful thing to do.
In January the UK government published a blueprint for modern digital government setting out the actions it will take to redesign public services to make them fit for the 21st century.
The word ‘digital’ has several meanings, but the UK government’s digital centre blueprint focuses too much on digital as a channel.
There’s lots of talk of websites, apps, and phone notifications. There’s very little about the physical and human interactions with the same public services or how these could be improved by modern, digital ways of working.
This risks:
poorer public services for millions of people,
a less resilient state,
a missed opportunity to lead on building a government that is truly fit for the 21st century.
As the government further develops its blueprint it needs to take a more radical look at how modern technology and modern ways of working can improve public services for many more people.
Public services need more than digital channels
Most public services are accessed through a mix of physical and digital channels.
GOV.UK is great for transacting with government online, but many people and many services need more than a website,
People move back and forth between these different channels based on their needs, the requirements of the service, and changing circumstances. This can happen as part of the same journey. To give two examples:
a passport application might start online, the passport office might ask the applicants in for a face-face interview, if the application is successful a physical document will arrive in the post and a digital record will be recorded for future use.
someone might start their Universal Credit application online but, while their application is being processed, their circumstances change. Perhaps they no longer have enough money for a mobile contract or lose dexterity in their fingers. To continue their application they might ask a friend for help, go to their local Jobcentre, or go to their local Citizens Advice.
Each of the interactions in those examples might be supported by modern digital technologies, and there’s some underlying infrastructure tracking and maintaining the passport and benefits applications, but the channels are both physical and digital with people doing what they need to do to get the services they need.
If a person goes to some Citizen Advice centres then the advisor may use a digital tool called Caddy to assist them in giving advice. At all times the person wanting help talks with another human.
The state of digital government review misses non-digital channels and digital ways of working
It contains no assessment of the state of the government’s non-digital channels.
The review mentions the public’s level of satisfaction with using public services through digital channels but has no information about the public’s satisfaction with either whole of public services or of using public services in non-digital channels. Has that fallen more? Or less? Does anyone know?
The review contains figures on the amount of daily transactions with central government services on gov.uk, but no figures on the amount of total daily transactions through other channels. Has no one bothered to collect this?
The review talks about a lack of common technical components, but has no thoughts on the non-technical components that are used by multiple public services. These are things like libraries, call centres, schools, hospitals, town halls, post offices &c &c. Could they be shared more? Or less? Are there any gaps in provision or opportunities to improve them?
The review misses modern, digital ways of working and whether those capabilities are widespread across the government.
I could go on.
This is the literal front door of the NHS at my local GP surgery. The UK government’s state of digital government review would count this surgery as a ‘great’ service if it had a user-friendly and efficient website that met web accessibility standards.
The digital centre blueprint continues along the same lines
It mentions digital inclusion – some statistics that are not in either report: 12.1 million UK adults have very low digital capabilities, 23% of UK households struggle to afford communication services – and says that the government will ensure “as many people as possible can access public services digitally, and that we support the digitally excluded.”.
But the state of digital government review did not assess any existing support for these millions of people and none of the actions in the blueprint’s roadmap describe whether any changes might be needed to improve this support.
Slightly bizarrely neither the review or blueprint seems to have an assessment of the UK population and the types of public services they might need now, or in the future. People’s voices are mostly absent.
The blueprint has a roadmap of next steps but this focuses on new online services: an app, a digital wallet, a chatbot.
There is one action for “piloting improvements on how we can better manage a long-term health condition or disability”, but this is described as supporting the government’s goal to Get Britain Working. It is not about helping people with long-term health conditions get the many other public services they need and deserve.
This video was used at the launch to bring the digital centre blueprint. Without going into nerdy detail it’s genuinely really thoughtful on how to build good online services, but where are the human interactions between people and the state?
The risks of the current focus
This focus of the blueprint for digital government on online services creates a number of risks. I’m neither daft or arrogant enough to try and identify them all, but here are three that are high in my mind.
Poorer public services for millions of people
Government needs to prioritise its resources. If the teams in government that design and build public services are told to focus on websites and apps then the other parts of public services will receive less attention
While anyone reading this post online may think that they can survive using only online public services any of our circumstances can change whether it be due to losing a job, suffering an accident, catching a long-term disease, or needing to care for a friend or relative.
Given the UK’s aging population these numbers will only rise and the issues will only become more politically salient.
Public services that can be used online or offline will make the UK more resilient against a range of threats.
Digital technologies are prone to cybersecurity attacks and simple mistakes in ways that humans and physical places are not. A failure in a single national shared component could cause public services to fail across the country.
Meanwhile other threats are increasing.
The new age of authoritarian leaders in countries like Afghanistan, India, Turkey and the USA are using online services and digital infrastructure against their enemies.
So far the UK has struggled to build its own digital infrastructure, which would reduce the threat of similar actions here, but it has physical infrastructure.
Missing the opportunity to lead on building a government that is truly fit for the 21st century
While there is a lot of attention on AI and automation at the moment it is clear that future public services will include both technology and humans.
Don’t just take my word for it. In 2024 Klarna got a lot of press by announcing that they were cutting staff because AI could do the job. Just a few months later they had an epiphany and realised that humans will play a key role in any organisation of the future so started hiring people back. Sadly, that got less press coverage so maybe the UK government didn’t see it.
Learning how to design and deliver public services that support people to interact with government both online and offline will help position the UK to lead in future public services. It will set the UK up for the long-term, rather than something that could just be a short-term craze.
The digital centre blueprint needs to evolve
The digital centre blueprint isn’t finished, but it needs to evolve. Hopefully when that happens it expands beyond its narrow focus on the online parts of public services.
Since the blueprint was published the UK government has decided to cut public spending further. So, it is becoming even more important that the money that will be spent is spent well and on things that create the best, long-term impact.
Simply focussing on more websites, apps and notifications won’t deliver the great public services the UK public needs and deserves. The UK government needs to place a lot more focus on using modern ways of working to design and deliver public services that work for everyone.
The other day I got asked a question: what public datasets will have high impact on AI in the UK? The person asking me was pulling together ideas for the UK’s AI Opportunities Action Plan.
Hmm. It is a surprisingly big question, not least as the AI opportunities action plan is not very specific in how or why it wants the UK to inject AI into its veins.
think about five areas of AI that publishing data could impact:
unlocking other datasets
supporting accountability and innovation
models for government priorities
models for particular domains
models with particular capabilities
five recommended datasets to unlock capabilities that AI investors and firms don’t seem to be working on, yet
navigating the UK’s legal and regulatory framework
seeing the UK as the administrative state does
understanding what is generally accepted as a fact in the UK
understanding how people in the UK communicate with each other
understanding how people in the UK experience public services
remember that publishing data doesn’t lead to magic
What is the AI Opportunities Action Plan recommendation about datasets
The top-line of recommendation 7 is to:
Rapidly identify at least 5 high-impact public datasets it will seek to make available to AI researchers and innovators
The description says:
Prioritisation should consider the potential economic and social value of the data, as well as public trust, national security, privacy, ethics, and data protection considerations. We should explore use of synthetic data generation techniques to construct privacy-preserving versions of highly sensitive data sets. Government data sets are a public asset, and careful consideration should be given to their valuation.
There are other recommendations related to data, but this one is key to getting things moving.
What does “high-impact” mean?
The recommendation talks about “high-impact” datasets but does not clearly define what type of impact is being looked for. Many conversations in this area tend to simplistically focus on data for developing new AI models but if we squint a bit deeper then five high-level areas might be interesting:
Datasets that unlock other datasets
Datasets about AI models and products to support transparency, accountability and innovation
Datasets that make it easier to develop AI models and products needed for government’s priorities
Datasets that make it easier to develop AI models and products in particular domains
Datasets that make it easier to develop AI models and products with particular capabilities
All of these areas align with the UK government’s overarching goal of (economic) growth, but they get there in different ways and might generate other benefits as well as impact for AI.
The first area is to focus on datasets that unlock other datasets. This is similar to the approach that the EU has taken on high-value datasets. The EU is making specific datasets in geospatial, earth observation and environment, meteorological, statistics, companies and mobility domains available based on analysis that says it will create billions of economic value. Rather than looking for ideas for new datasets the UK government could simply copy this work as these datasets could have similarly high economic value for the UK.
The second is to focus on datasets about AI models and products, for example datasheets, model cards, system cards or information about service performance. These kinds of datasets can drive both accountability and innovation. The UK government could be a lot more radical in its work to improve transparency about AI models and usage, but I suspect this isn’t the desired impact of the AI Action Plan.
The third area identifies datasets that would contribute to developing AI models that help deliver the government’s priorities, for example the five missions. The missions are still being described to the public in quite broad terms so these datasets are best identified by teams working on the government’s missions and other priorities. The AI team should probably just speak with the mission teams.
The fourth area is to focus on datasets that help build AI products in a domain. For example in the domain of medical diagnosis Moorfields Hospital collected eye scans for use in identifying or predicting a range of medical conditions, people who want to improve how major infrastructure projects are managed might want to make data available about how big things get done, or people who want to improve public sector procurement/delivery might want to look at procurement data. These datasets are best identified by teams working in those domains. The government will need to select the domains it prioritises.
The fifth area is to focus on datasets that help develop domains of capability for AI tools. These datasets might be used to develop models or as technical components that can be incorporated into AI products – for example as filters, or as authoritative knowledge bases that can be looked up when creating a response.
The precise technical architectures will depend upon AI researchers and innovators.
These capabilities can simultaneously benefit a wide range of other domains and AI products so could create a lot of impact across the previous four areas.
Given this, the following section recommends five datasets in this fifth area, with a leaning towards capabilities that AI investors and firms are struggling do by themselves.
Suggestions for datasets that unlock domains of AI capabilities
Legal data
Example dataset: legislation data on legislation.gov.uk
Desired impact/outcome for AI: More AI models and products that can help users navigate both the UK’s legislation as written and the intent behind the rules
Data holder(s): National Archives, MoJ, Parliament, regulators
Getting started: Some of this data is already modelled – for example through legislation.gov.uk – but requires annotating and contextualising for use by AI researchers and innovators.
The law can change more regularly than many people expect, case law evolves on a daily basis. So developing products that have this capability is likely to encourage the creation of technical architectures that use multiple small components and models that can be iterated at different frequencies, and require UI/UX design that helps users understand the limitations of the tools they are using.
The government’s guide to making legislation describes other information created during the legislation drafting process that could be turned into data and annotated for use in AI processes. For example the policy and factual background to a piece of legislation. This could further enrich AI models and products.
Beyond legislative data this provides a path to move into regulatory guidance, government policies, and other legal datasets.
The National Archives have expertise in the required activities and data.
AI models and products won’t know the law like fictional character Neo in The Matrix gets to know kung fu. Our world is more complicated than the movies.
Authoritative reference data about the UK
Example dataset: Address data
Desired impact/outcome: More AI models and products that understand how to navigate, interact with and see the UK as the administrative state does
Data holder(s): Ordnance Survey, ONS, central and devolved government departments, local government, Met Office, Highways England, Transport Scotland, etcetera
Getting started: Some of this data is already available – eg national statistics – but will need annotating and contextualising for use by AI researchers and innovators.
Some of this data is behind paywall and copyright restrictions, for example Ordnance Survey’s geospatial data. This requires additional work to create a sustainable funding model that makes the data available for use by AI researchers and innovators. This will reduce financial and IP barriers for AI model developers and help level the playing field between large AI firms and smaller organisations.
Other data – for example planning rules or benefits eligibility rules – may not be held in digital formats and will require work to create data standards, digitise the data, develop funding models and then annotate and contextualise for use in AI. MHCLG’s digital planning programme is doing some of this work for planning data.
This work will need to cater for the leeway in some of these rules where humans will make decisions and rules cannot be cleanly turned into data.
AI models and products that use this data will require additional work to ensure both that models appropriately use authoritative factual data and that this usage is appropriately communicated to service users. This will help service users understand the source and quality of the data.
Desired impact/outcome: More AI models and products that understand what is generally accepted as a fact in the UK
Data holder(s): Non-UK NSOs (national statistics organisations), trustworthy news sources
Getting started: Investment will be required to support some data holders to publish and annotate this data for use in AI models and products.
AI models and products that use this data will require additional work to ensure both that models appropriately use authoritative factual data and that this usage is communicated to service users in ways that help them understand the source and quality of the data.
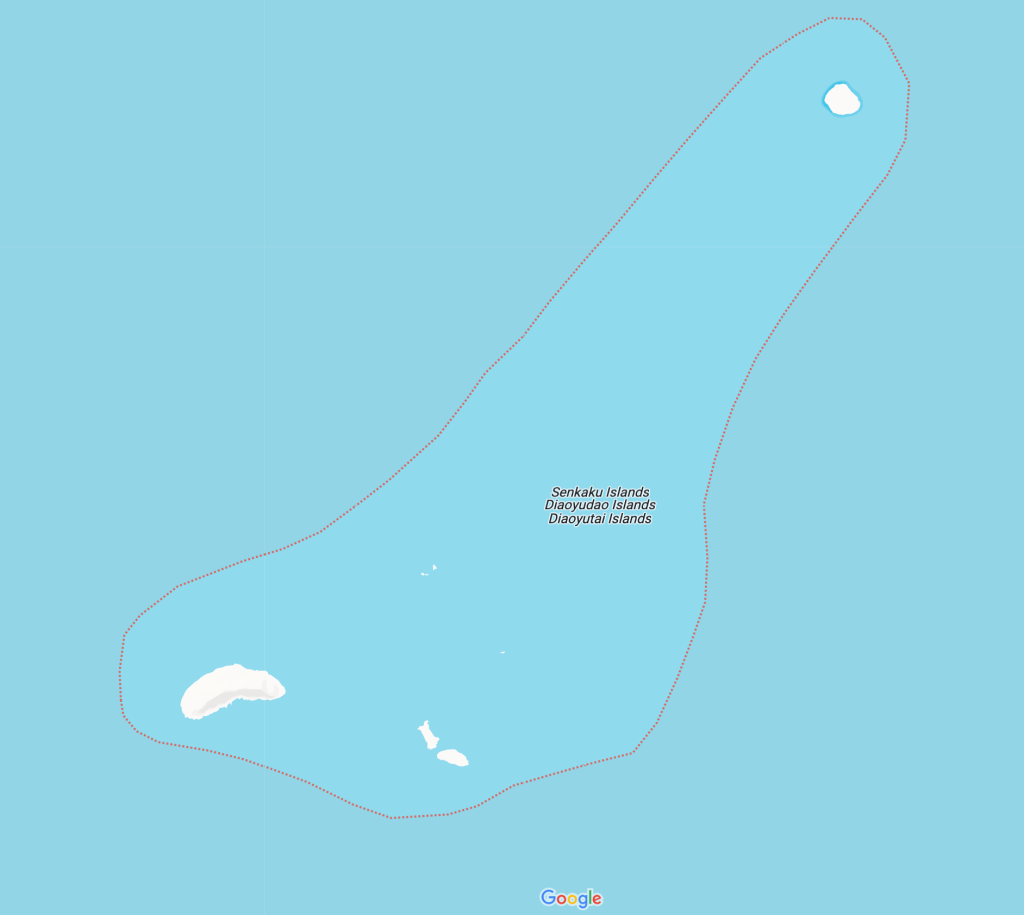
Some facts are disputed between or within countries. AI models and products will need to be developed that can navigate these disputes.
Full Fact have developed a methodology for identifying, collecting and annotating this data so that it is useful for AI researchers and innovators. Government could get started by talking with that team.
Some facts about the world are contested. For example China, Japan and Taiwan dispute both the ownership and names of the Sentaku / Diaoyudao / Diayutai / Tiaoyutai Islands. Image from Google Maps.
Cultural data about the UK
Example dataset: Transcripts of a diverse range of television soap operas and sitcoms
Desired impact/outcome: More AI models and products that understand how people in the UK communicate with each other.
Data holder(s): BBC, ITV, Channel 4, National Archives, British Library
Getting started: The Action Plan recommended that the government make a “copyright-cleared British media asset training data set” available. This is a broad description.
The emphasis should be on making data available that will help AI researchers and innovators develop AI models and products that understand how the UK’s diverse publics communicate with each other.
Identifying a wide range of television shows that depict the lives of people from different and overlapping communities across the UK’s four nations would help achieve this goal.
Government could get started by talking with both creative industry organisations and workers in creative industries.
What use is an AI model that can’t communicate with Alma?
Public service complaints data
Example dataset: Feedback data collected by gov.uk services
Desired impact/outcome: More AI models and products that understand how people in the UK experience public services.
Data holder(s): Central government departments, local authorities, regulators, politicians
Getting started: People make complaints when things do not work. These complaints help us both understand how people communicate when they are unhappy, frustrated or even angry. They also help identify where things can be improved and how people use and experience services.
These complaints might be made in a number of different places and times. For example, while people are using an online service on gov.uk, in person at a public sector building like a town hall or library, to regulators, or to politicians.
People are more likely to make these complaints if they believe they will be heard, so this data tends not to be fully representative and is likely to over-represent majority groups. Statistical techniques can help counter this bias but public sector organisations can also invest in improving feedback processes to provide a more representative dataset. Done well this will also have the direct benefit of improving public services. Perhaps that improvement should be the primary goal.
Complaints data is sensitive so synthetic data will need to be created and appropriate governance put in place to ensure that the data is only used in ways aligned with the purposes for which it has been provided
Government could get started by exploring the feedback processes and data that should be collected by the gov.uk channel used by some public services.
Publishing data doesn’t make magic happen
So, some recommendations for datasets to help develop capabilities in AI models and products that would have a high impact in the UK. Some of those recommendations will be useful, others will probably turn out to be useless, but there’s another important thing to remember.
Simply making data available does not mean that people will use it in ways that you expect.
Luckily for the government it can act like a system, intervening in a range of ways and places to reduce harms and create more desirable outcomes. Government’s roles as a regulator, funder, user and provider of AI models and products will all be useful to help deliver on the outcomes described in this post.
Those, and other, roles are things that the government will need to lean into if it wants the AI being mainlined into the UK’s veins to lead to better lives for everyone in the UK.
In its 2024 manifesto the UK Labour Party promised to build a National Data Library that would:
“bring together existing research programmes and help deliver data-driven public services, whilst maintaining strong safeguards and ensuring all of the public benefit.”
Great, there’s a lot to do on data in the UK. But, unfortunately the manifesto commitment is a pretty broad scope and the term ‘library’ can be confusing. It is not surprising that people are finding it hard to agree what to do next.
Here’s a suggestion for what the “National Data Library” should be and how it could get started.
The National Data Library should help public sector teams deliver trustworthy data services by providing guidance, reusable platforms / technical components, and growing communities of practice.
It should start with practical work to build and improve the government’s existing data services. This will help it learn what is needed to deliver trustworthy data services across the public sector.
The visions and priorities for the library are broad, that is making it hard to define
At a political level the description in the manifesto might seem to make sense, but when you poke at it the sentence starts to fall apart.
The concepts of bringing together “existing research programmes” and helping “deliver data-driven public services” are different.
Public services tend to need access to reference data, information about rules, and to collect and process data from and about individuals and businesses that use the service. They are shaped by democratic debate and a range of legislation including data protection and administrative law. There are many existing public service-focussed data initiatives inside the government.
Research programmes tend to need access to large datasets from one or more organisations. They have oversight, such as research ethics committees, and researchers are likely to be accredited. A research programme is a lot more likely to seek informed consent, for both participation in the research and data use, than a public service. There are many existing research programmes running in universities, philanthropic and public sector organisations.
The original proposal for a UK National Data Library, from centre-right think tank Onward, said that it should be “a centralised, secure platform to collate high-quality data for scientists and [AI] start-ups”. While data for scientists might mean the same thing as data for research programmes, data for AI start-ups certainly does not. So, that is another set of needs to understand, prioritise and design for.
Finally, the Labour government places an emphasis on mission-led government with a set of initiatives that cut across government departments, other parts of the public sector and wider society.
These missions will rely on data to understand problems, make change, and report progress to the public (perhaps as official statistics) and senior politicians. To deliver on their missions teams are also likely to need to use data in ways that create impact that differ from people’s classic conception of a public service. So that is another set of things to think about.
And the library will prioritise between all of these different areas and their possible use cases while maintaining strong safeguards and ensuring all of the public benefit?
And the idea of a data library has been leading people in confusing directions
Meanwhile there’s another problem. The term ‘library’ seems to be confusing things.
Like most people who does policy – and other things – I can take a strange joy from exploring definitions and meanings, but the term ‘library’ seems to be proving unhelpful. People seem to be thinking of it as a single object or thing that contains all the data.
Box-and-wire diagrams are in fashion this year, aren’t they?
A central data portal with a catalogue for all of the data seems to be a popular idea.
Yet a lesson we have learnt is that a single, big portal will not meet people’s varying needs when publishing data, searching for it, or making use of it. A broad scope like the one set out in the Labour manifesto needs lots of catalogues, portals and other things to ensure that data gets to people who need it and are allowed to use it.
A less popular idea, but an idea that is still visible in policy circles, is a single technology platform – such as the one described by Onward. This would be a platform where all of the data is accessible with common governance, technology and standards.
Unfortunately a single platform for data would be a great target for hackers, stifle innovation, and change democratic accountability in ways that are hard to predict.
Government is not one organisation. It is thousands of organisations with varying goals, that fulfill their democratic lines of accountability in different ways. This means that different governance, technology and standards will often be appropriate. The world of using health data for medical research is pretty different to the world of using data to improve local authority services for planning applications.
And, just like a central portal, a central platform would not be able to meet the wide range of needs of data users.
Given the focus on the word ‘library‘ I’m even expecting someone to be daft enough to suggest library cards, perhaps with fines for people who don’t ‘return’ a particular piece of data on schedule…
The UK needs an approach that works for many different contexts and that builds on the work that is already being done by teams across the country.
There is not much discussion of the need to improve the government’s existing data services
Lots of data services already exist across the UK that might fall into the National Data Library’s broad scope.
Each of these services has stakeholders with different behaviours, needs, motivations and skills. They also have delivery teams with different capabilities, strengths, and weaknesses. In the different services data might use different standards, because they meet different needs. There are multiple legal and governance frameworks. Data protection is not the only law at play here.
Some of these existing services are great, some are heading in the right direction, some don’t seem to understand their stakeholders, and some simply don’t exist even when they should.
Rather than building a single thing, the National Data Library should make it easier for teams across the public sector to deliver data services like these.
The National Data Library needs to help people deliver trustworthy data services
Despite the variations between these services there will be some shared problems and lessons that have been learnt and shared for how they can be tackled. This is an area where the National Data Library could usefully focus.
Here are some ideas for the support capabilities that could be provided:
guidebooks and manuals for how to design trustworthy data services and their associated governance and oversight mechanisms. Organisations can then use these core practices or adapt and build on them in their own context.
a shared library of user research to make it easier for data service teams to understand the range of people impacted by their work such as researchers, data analysts, policymakers, and members of the public.
a design system and patterns, the data design patterns that currently exist tend to have been developed outsidethe public sector.
reusable, tested and well-maintained components,for example platforms – or simpler technical libraries – for publishing data or information about research projects, tools that make it easy to create data portals, verify data against standards, or understand data bias and its potential discriminatory effects.
a data linking service, guidance, public engagement, transparency and approval mechanisms for linking data across government and/or non-government research infrastructures. Perhaps London shows a way?
data transparency and control services, that empower individuals, communities and regulators to understand and control how data is used at times and places that are relevant to them.
a National Data Academy that provides training courses and coaching in data skills
funding, to support experiments, pilots and discoveries in under-resourced public sector organisations.
communities of practice to maintain and improve all of the above. Some of these communities already exist, both formally and informally, but many need more support. Communities of practice could usefully exist in teams building data services and in the groups of people – like researchers and start-ups – that use them.
Design patterns are a way that digital team teams communicate repeatable solutions to common problems. These images are from IF’s design pattern catalogue.
To stress. These are just ideas.
Other people might have better ideas. A team that helped people deliver trustworthy data services would have to learn what was needed by:
doing the practical work to build/improve some data services themselves,
working with existing teams to understand their challenges,
and listening to various viewpoints from outside the public sector.
This was roughly how GDS got going in improving digital services.
A data library team would also need to be careful of the overlap with existing things that help with the goal of delivering trustworthy data services. For example the ICO’s regulatory guidance on data protection, HRA’s advice on health research, or even the OSR regulatory guidance and ONS guidebook’s on statistics.
But these are not insurmountable challenges and, from my own work across government, I’m confident that there are many needs for support that are not being met and many opportunities to tackle the problems together.
The existing data service teams across government can then use these new support capabilities to help them build trustworthy data services better, cheaper and faster.
Getting things started
It is important that one of things a national data library team that helps people deliver trustworthy services starts with is some practical work to help public sector organisations improve or build some data services. This would deliver some early impact, create momentum, and generate learnings and capabilities in that core team.
In selecting these data services it will need to look for some variety. This will help illuminate the problem / opportunity space.
The final decisions for where to start should be based on government priorities but – from my own knowledge about common problems / opportunities – perhaps it could include:
a data service that openly provides access to authoritative, non-personal data held by the public sector that could be widely used by public services and startups, for example address data
a data service that provides authorised organisations and researchers with secure access to attributes about individuals, for example their age or eligibility for benefits
a platform that helps research programmes publish accessible information about research projects throughout their lifecycle so that individuals and communities can understand how they are impacted by research activities
a platform that helps research programmes publish accessible information about the data they hold and types of research they support so that researchers can find what they need more easily
a service that makes it easier for multiple local authorities to publish data locally and then aggregates it for use nationally, for example information about elections or places where clean energy infrastructure could be built
By doing this work the national data library team can start to develop the much-needed guides, components and communities of practice that can deliver more trustworthy data services across the public sector.
The National Data Library should help people deliver trustworthy data services
The commitment behind the National Data Library provides an opportunity to improve how the UK public sector, researchers and startups use public sector data, but this opportunity will not be realised if the UK ends up in endless abstract policy debates, workshops and roundtables or – even worse – building big new central portals and technical platforms that everyone is told to use.
Building capabilities that support existing teams to deliver more trustworthy data services across the public sector will be far more impactful and start to deliver the change that is needed.
Want to read more stuff?
If you’re interested in the National Data Library then here are some links I found useful when forming my views:
The MHCLG Planning Data platform manual’s approach to data quality, which brings the government framework into the planning data context
And thanks to Ellie, Steve, Andy and others who I bounced around these ideas with as I was writing them up. All mistakes and idiocies are always my own.
Yesterday I was skimming the UK Department for Work and Pensions (DWP) latest whitepaper, called “Get Britain Working”, to see how they planned to use technology to help them deliver the policies and public services in it.
In doing so I was struck, not for the first time, by the wide number of ways in which the words ‘digital’ and ‘data’ are used across the public sector. As an experiment I thought I’d try to categorise them. This post is about ‘data‘, I might publish a similar post about ‘digital‘.
The categories in this whitepaper will be far, far, away from a complete list and all categorisations are loaded in some way, but some light grouping came up with eight categories that were interesting to me:
data as an input to and output of scientific research
data as an input to and output of a tool or public service
data produced as an official statistic
data produced for policy development
data produced for service planning
data to describe a type of computer system
data as something that needs governance and could be used for many purposes
It’s interesting to consider which of these categories of data uses the UK has the capability to do repeatedly to a decent standard, and which are the ones where more work might be required.
Data as an input to and output of scientific research
There was one case of data being an output from a scientific research study. Data will be an input to this study too. There are a range of legal, ethical and professional frameworks guiding scientific research.
Research is one of the purposes that the National Data Library is meant to support .The current text of the Data Use and Access bill includes a change to the legal definition of research. The change broadens the definition of research beyond scientific research in the public interest.
“a place-based real-world evidence study … aims to evaluate the effectiveness of tirzepatide on obesity and its impact on obesity-related conditions in a real-world setting… As well as data on patient outcomes, such as a reduction in rates or even reversal of conditions such as diabetes, CVD and poor mental health, the study will also …”
Data as an input to and output of a tool or public service
There was one case of a new tool that uses data to produce data.
In this case the tool would provide a prediction that an individual is at risk of not being in education, employment or training. This might also be referred to as a public service that includes automated decision making (ADM).
This kind of tool comes with multiple risks, such as: unfairness and discrimination against some communities, or that the prediction is treated with too much certainty and used inappropriately by other tools, people or organisations when it might turn out to be flat out wrong.
Data-driven public services is one of the purposes that the National Data Library is meant to support and that the DSIT digital centre works on with departmental teams like DWP Digital.
“We will publish new guidance on using a Risk of NEET Indicator (RONI) approach and provide a new data tool so that local authorities can better identify those at risk of becoming disengaged and put preventative measures in place”.
“Under the accountability and data sharing frameworks of a future Youth Guarantee, the college informs the Mayoral Combined Authority that Luca is at risk of not being in education, employment or training.
A local, youth-focused community organisation commissioned by the Mayoral Combined Authority reaches out to Luca to offer support and encouragement to re-engage and explore his employment or further education options”
Data produced as an official statistic
There were several references to data that, when you follow the footnotes, has been produced as an official statistic.
Official statistics are independently regulated by the Office for Statistics Regulation and there is a community of practitioners in and around the public sector.
“Data shows that only around 31% of prison leavers are in employment 6 months after release and 46% are employed in the 6 months following completion of a community sentence.”
“While many mothers want to care for their children full time, survey data indicates around half of non-working mothers would prefer to work”
“The latest available data shows that the relative poverty rate (after housing costs) of children in households where all adults work was 14%, compared to 75% for children living in households where no adults work”
Data produced for policy development
There were multiple references to data being used to help develop policies. It is unclear whether this data would be produced to similar methods and standards as official statistics or whether some other approach would be used.
While official statistics are openly published, data for policy development might be kept within the public sector and not published transparently. Often data for policy development comes from multiple sources and is linked together and analysed to find insights.
“The government wants local areas to have improved data to understand local population needs and to help design future programmes. We also need better data to track outcomes and develop the evidence base”
“We will continue to engage the expert Labour Market Advisory Board announced by the Secretary of State for Work and Pensions to provide the government with insight, ideas, and challenge. The immediate priorities of the Board…include job quality and progression, opportunity and equalities, health and inactivity, regional inequalities and data”
“By linking migration data with skills and employment policy, we will ensure that training in England is aligned to labour market needs”
“It will draw on local and regional vacancy data and Local Skills Improvement Plans (LSIPs) to inform its skills needs assessments”
Data produced for service planning
There were a couple of places where data appears to be being used to help plan and carry out operational services.
This might be produced using similar methods as data for policy development, but it typically has a different audience with different capabilities and needs.
“This will work with Integrated Care Board leaders to further reduce waiting times and improve data and metrics and referral pathways to wider support services.”
“In August, the Department for Education introduced new statutory guidance for schools and local authorities on improving attendance, supported by comprehensive near real-time data in England”
Data to describe a type of computer system
There was one reference to a type of computer system for data.
A team developing and maintaining a system like this might follow guidance from the DSIT digital centre or, as this particular system is in the health sector, guidance produced by the Department for Health and Social Care or NHS England.
“as well as exploring opportunities to utilise the data platform created by Our Future Health in partnership with the NHS”
Data as something that needs governance and could be used for many purposes
There were a couple of broad references to data being information that could be used for many things, but that needed appropriate governance.
Local Get Britain Working Plans trailblazers that require “governance and management – including accountabilities and responsibilities across partners, and arrangements for data sharing”
Youth guarantee trailblazers that require “Governance and management – including accountabilities and responsibilities across partners, arrangements for making the best use of data, and management structures.“
Data as an enabler for other unspecified things
And a couple of references to data being something that could enable other, loosely specified, things. These examples seemed to differ from the above as they did not explicitly mention aspects of governance.
“Developing further tools will also provide the foundational data to enable further opportunities to transform the services”
“To enable [more enhanced collaboration between Jobcentre Plus and the National Careers Service], a new England-wide data sharing agreement between the Department for Education and DWP will be put in place from winter 2024”
In 2021 the UK government’s Geospatial Commission prepared a briefing paper for some discussions about address data. It has been released to the journalist James O’Malley after a freedom of information request.
The paper was prepared in response to the long-running campaign asking the government to deliver on politicalcommitments to make the list of UK addresses – and other non-personal geospatial data – freely available. People could then use the data to improve public services or build innovative new businesses.
The paper includes the mind-boggling statement that a government project in 2016 estimated that the cost to the UK government of buying back UK address data from the Royal Mail would be £487m.
Yes, you read that right. That figure was four hundred and eighty seven million pounds.
I made this very amusing image using a highly sophisticated meme generator
It’s a big number and – if true – one that would call into question the whole campaign.
But, it doesn’t hold up to critical scrutiny and, unfortunately, the 2021 paper repeats this estimate without questioning it.
The civil service needs to be less credulous when it comes to claims over the financial value of data assets, and the UK government needs some fresh analysis.
Valuing intangible assets is difficult, valuing a commercial product is much easier
Valuing intangible assets, like data, is difficult. I’m such a fun person that I read books and academic papers about the different ways it can be done.
But, to the Royal Mail address data is fundamentally a commercial product line. Or, to put it another way, a small business within their larger business.
At the simplest level the product is created when Royal Mail adds postcodes to the addresses created by local authorities. The Royal Mail then sells the resulting data product – under a commercial licence – both back to the government and onto other businesses.
A simplified view of the address creation process for England and Wales. Image created by Anna Powell-Smith of the Centre for Public Data. For a more detailed explanation read Owen Boswarva’s primer.
This product is regulated. Every year it brings in about £30m of revenue and generates about £3m in profit.
A valuation of £487 does not pass the ‘smell test’
A price of £487m values that product line at a multiple of 162 (one hundred and sixty two) times its yearly profit of £3m.
If the valuation is true then that single product line would account for 15% (fifteen percent) of the current market capitalisation of the Royal Mail’s owner, IDS (International Distribution Services).
To put that further into perspective the whole of the IDS business has a turnover of £12bn. 400 (four hundred) times the turnover of this product line of address data. Yet somehow this small product line is 15% of the market capitalisation?
The IDS annual financial report does not even mention address data. It is too small a part of their overall business.
The valuation discussed by the UK government’s Geospatial Commission in their paper makes no sense. It does not pass the smell test.
We can imagine some negotiations
But, let’s look deeper. I can imagine the Royal Mail’s negotiators asking for such a large figure from the government. Why wouldn’t you try?
The Royal Mail might have talked about the economic value that better and more accessible address data could create for the UK economy. They might be thinking that they hold a unique asset and have the UK government over a metaphorical barrel. They might have argued that the £3m a year in profit was necessary for the financial viability of the Royal Mail. The negotiators might have said that only the Royal Mail can create addresses that work for deliveries around the country and that it was a vital part of delivering the UK’s universal postal service.
This is what OpenAI’s DALL-E thinks tough business negotiations would look like. So tough that there’s not even a packet of biscuits on the table.
But the argument in return is that most of the effort that goes into creating address data comes from local government officials around the country. That if the address data they create is good enough for other services and other delivery firms then it can be good enough for the Royal Mail too. And, most importantly, the small amount of financial value that this product line creates for the Royal Mail’s own business.
But the negotiations should have simply started with a fair market value
But, to draw a comparison to the physical world, this type of negotiation would also have been the wrong starting point.
If the government needed to compulsorily purchase a piece of land or a business to build some physical infrastructure the discussion starts at the market value that a willing seller might find on the open market. The buyer selling a piece of land does not get to claim a percentage of the larger economic value that the new infrastructure could create for society. They simply get to sell their asset at a fair price.
The negotiations for selling the Postcode Address File back into the public sector should have started the same way. This would have cut through the complexity of data valuation.
No other buyer would pay £487m for a regulated product that creates £3m in profit a year, a multiple of 162. It is not the market value.
UK government and Royal Mail need to be realistic about the market value of address data
The campaign to open up UK address data is supported across the political spectrum. Most recently it was supported by peers from four political parties – Labour, Conservatives, Greens and Liberal Democrats.
A Minister from the previous government rejected their request and referenced this flawed report from 2016 that includes this unrealistic figure of £487m. The Minister should have asked the civil servants to start again.
The new UK government is building a digital centre for government and plans to create a National Data Library to deliver better services to people, researchers and businesses. That National Data Library could create significant economic and social value for the UK, particularly if it opens up foundational datasets, such as geospatial data. Other countries are doing this and the UK is falling behind.
As part of that work the Ministers from the new Labour government should ask their officials to stop relying on their flawed, old work and carry out a fresh analysis of address data.
‘Public good’ is a term that is frequently used in debates about data, statistics and AI. It has featured prominently in UK government policy and strategy, but the term isn’t always well defined or explored.
But in the UK it can seem like there is little recognition that there are different uses of the term ‘public good’ in debates elsewhere in the world, particularly with the emergence of the concept of ‘digital public good’. Sadly UK policy seems to have gradually become more insular over the last decade as the country has wrangled with the results of the Brexit referendum and a seemingly never-ending carousel of ministers with responsibility for this area.
It seemed a good time to explore the concept of ‘public good’ a bit more., soJob de Roij and I from the RSS’s Data Ethics and Governance section have organised a couple of online events with speakers with expertise in both the UK and more globally.
While some work has been undertaken to unpick this term by understanding how the UK public think of it, and to review how the public good can be enhanced to support policy makers, regulators and practitioners, there is more work to be done to ensure that statistics and statistical processes truly serve the good of the UK public.
What do we mean by “serving the public good”? What are the gaps in our understanding of how to make things serve the public good? How do we fill those gaps?
Event 2: As a public good
Meanwhile there is growing attention around the world to the concept of ‘digital public goods’.
The UN defines digital public goods as “solutions and systems that enable the effective provision of essential society-wide functions and services in the public and private sectors”.
Identity assurance and payment systems are well-known examples of digital public goods. Certificate transparency, which underpins website security, a less well-known example.
In the world of statistics things like national statistics or the new ONS Integrated Data Service could be grouped into the concept of digital public goods. But what other kinds of digital public goods might, or should, exist that are relevant to statisticians?
What is a digital public good? When is data, AI and statistics a public good, and when is it not? Are any digital public goods that could help statisticians serve the public good missing? How do we build and govern digital public goods?
Further reading
If you want to read more about this topic then some links are below. Skeet or mail me if you think other things should be added.
The UK has an official list of building addresses and their locations – ‘address data’. This data is a vital resource for building public and private services that rely on locations, and is part of our national data infrastructure. At the moment, the UK’s address data is expensive, hard to access, not always accurate, and hard to correct. This causes problems for businesses and other organisations that rely on address data – and ultimately it affects us all.
The debate had contributions from Labour, Liberal Democrat, Green and Conservative backbenchers. The Minister for the Conservative government then rejected the amendment.
Reading and watching back the debate made think about three things:
The government agreed to share deeper analysis, which is good news
But it misunderstands why previous attempts to recreate UK address file failed, that is bad news – and not just for addresses
The risks of openly publishing address data, or of not publishing it, are misunderstood
The government agreed to share deeper analysis
The Minister said that they were “very happy to share deeper analysis” of address data. This is good news, both because better evidence can create a better debate but also as it indicates that the government actually has some analysis.
The Geospatial Commission said they had no analysis
In 2022 the Geospatial Commission responded to a Freedom of Information (FOI) request by saying that it did not assess address data when preparing its strategy. Similarly in 2023, when the Geospatial Commission was agreeing a £31m contract with the Royal Mail, they said that they did not perform any analysis of the costs, benefits or alternative options.
There were some previous projects that did do deeper work. For example, in 2017 the government spent £500k, out of a potential budget of £5m, investigating how to create an open address file.
A map of open address data around the world from OpenAddresses.io
A misunderstanding of why previous attempts to recreate UK address data failed
The Minister referred to previous attempts to recreate the UK’s address data, saying
“the resulting dataset had, I am afraid, critical quality issues”.
Viscount camrose
As someone who spent part of 2014/15 working on a project to recreate the UK’s address data that was not why our project was stopped. The Minister might want to ask officials for more details as we learned some interesting lessons that the government needs to learn too.
The kind of innovation that government policy wanted to support
Our approach to recreating the UK’s address data was to start with data that the UK government already publishes. In line with the government’s “open by default” data policy, organisations like the Land Registry, Companies House, and the Valuation Office Agency spend money to make the data they hold available for other people to use. Some of this data contains address information.
We intended to make the bulk data available for free, and then generate just enough revenue for sustainability – perhaps from high volume users of the API. We set ourselves up as a not-for-profit company.
It was the kind of innovation that the government’s open by default policy is intended to support.
Much of the government’s open data was not ‘open’, this creates legal risks
Unfortunately we found that much of the government’s open data was not actually ‘open’.
The government’s copyright licence (the Open Government Licence, or OGL) excludes third party intellectual property rights. The third parties who hold IP rights in address data, Royal Mail and the Ordnance Survey, are litigious and many of the government organisations that published the data were unable to be clear on whether or not there was Royal Mail or Ordnance Survey rights in the data they published. We only used datasets where the publishing organisation told us it was ‘safe’.
But even though it was government organisations publishing the data they would not be liable if there was a legal issue. We would be. So we needed insurance cover.
But given the risks only one insurance company was willing to offer cover and that was on unrealistic terms. So, we stopped the project.
To put it another way, an innovative, not-for-profit business could not use the data that multiple government organisations published to support innovation, because another government organisation might take legal action.
There are new plans to publish more government data, they risk the same problems
Zooming forward in time from the ancient history of 2014/15 and back to the present day various UK government departments are currently making new plans to publish more government data.
This is because of initiatives like the Vallance report on pro-innovation regulation of technologies and a desire to support the UK’s AI industry. High-quality, authoritative government reference data is one way of reducing the hallucinations that the current generation of AI models suffer from. Sounds sensible, right?
But publishing widely used address data is a lot simpler and safer than much of the planned work, yet the government failed to do so in a way that allowed organisations to clearly understand what they legally could, or couldn’t, do with it. Will this new wave of government data come with instructions telling AI models and engineers not to do anything with addresses? And what other third party rights might be lurking in there? Or will government just make AI’s copyright issues even more complicated.
If the government does not understand why its previous attempts to publish data did not yield the desired benefits then I fear a lot more wasted money in the future.
The risks of openly publishing address data are misunderstood
In the debate Lord Bassam said
“there is a balance to be struck between privacy issues and the need to ensure that service delivery and commercial activity operate on a level playing field”
LORD BASSAM
It is good that politicians consider privacy issues, but this misunderstands the risks.
Address data does not create new privacy risks
The list of addresses does not tell us where specific individuals live, the only personal data involved is likely to be those of people who name their business address after themselves. Instead address data tells us where people might live, work and play but not who is living, working or playing there.
(As an aside: I don’t want to imply that there are no risks of privacy, or other human rights, breaches with non-personal geographic data. For example in a separatist war in Sudan in 2011 atrocities were carried out because satellite data showed where particular groups of people were. But, hopefully, the UK is a long way from a separatist war and, let’s be honest, truly harmful actors will either simply buy the address data or use an illegal copy.)
The harms created by the lack of access to address data are more pressing
By contrast Lord Clement-Jones pointed out that
“The harms created by the lack of access to address data are more pressing”
LORD CLEMENT-JONEs
While Baroness Harding pointed at the issues with the current data quality saying:
“the quality of the data is not good enough….Anybody who has tried to build a service that delivers things to human beings in the physical world knows that errors in the database can cause huge problems. It might not feel like a huge problem if it concerns your latest Amazon delivery but, if it concerns the urgent dispatch of an ambulance, it is life and death.“
BARONNESS HARDING
Elsewhere the National Audit Office has pointed to the challenges of creating and using the shielding list of people with extreme clinical vulnerabilities during the pandemic. One of the challenges was inconsistent address data in different formats in different IT systems and organisations. This is one of the many challenges that opening up the official list of address data will help with, because over time more organisations will refer to and use the same reference data.
If the funding model changes then will quality drop?
There is one risk that was not discussed in the debate though.
If the maintenance and publication of address data is not funded from licence fees collected by Royal Mail and Ordnance Survey then will the quality drop?
This is where there is an important balance to be struck as people and organisations need the correct incentives to publish useful data.
Bluntly, this is the risk I worry about the most. Money is only one type of incentive but it is an important one in this context and it is one of the reasons why I’m so keen to see some deeper analysis of the current costs.
Experience tells me that the current costs are significantly overstated – particularly the Royal Mail who claim costs of ~£25m/year for ~300,000 changes/year. But however much the costs can be reduced it will still cost money to publish quality address data.
Making the publication of the data a statutory duty, as this amendment would have done, is one way to help tackle this risk. It requires the government to fund and do the work.
Perhaps the money might come from general taxation, and the increase in economic activity that will come from publishing the data? Or perhaps from a small increase in registration fees collected by local authorities who do most of the work to create addresses? Or a small increase in the Land Registry transaction fees, after all they handle nearly 50 million transactions per year?
Other countries have changed legacy business models, the UK should too
Whatever the final decision it will need some coordination and activity from a few public bodies willing and able to work together to publish address data as a public service.
And that’s where I hope the government is really focussing its analysis. Not on whether to publish address data for free, but on how to do it.
Because in the 21st century it is pretty sensible for high-income countries to make reference data, like addresses, as widely available as possible. That is why peers from so many different parties supported this amendment, and why so many other countries are doing the work.
The hard part of the work is changing the legacy business models and incentives of government organisations so that they make it happen. Other countries have done that, and it’s long past time for the UK to do the same.
Hello. This is the personal website of Peter K Wells. I do politics, policy and delivery to try to make data and technology benefit everyone. I also do bad jokes and music references.