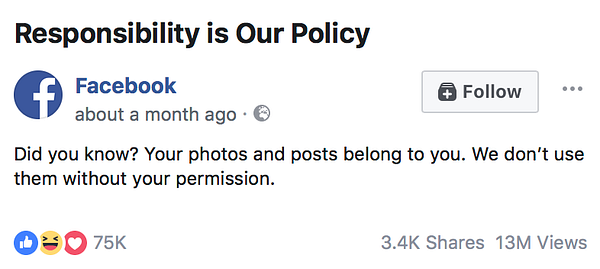
It told me that my “photos and posts” belong to me and that “[Facebook] won’t use them without [my] permission”.
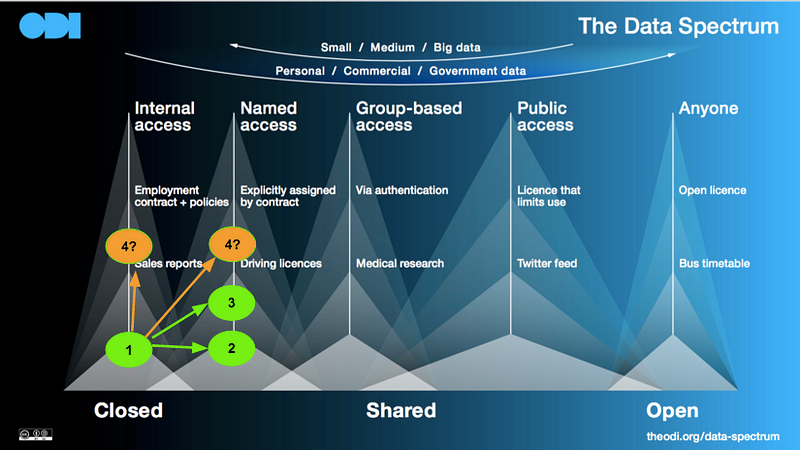
The same advert has appeared in the feed of friends and work colleagues based in the UK. It seems to be part of a campaign. Perhaps the campaign is related to the imminent European Union’s General Data Protection Regulation and the growing public awareness that there is debate around data, how it is used, and whether to trust those uses.
There is a similar message in Facebook’s terms and conditions saying:
“You own all of the content and information you post on Facebook, and you can control how it is shared through your privacy and application settings”.
Both messages are simplistic, at best. I don’t fully own or control the content I post on Facebook. It doesn’t only belong to or affect me. By over-simplifying its messaging Facebook, like many other organisations, is missing the chance to help explain how its services work and help us all make better decisions when sharing content.
Social media content is more complex than you might think
This will sound counter-intuitive to many. I mean shouldn’t I have control over my data on Facebook? It’s about me! I created it!!
Don’t be silly. Data ‘ownership’ is not as straightforward as it sounds. Most of my content on Facebook is not only about me. It is about other people too.

My list of friends is a list of relationships with other people, people tag someone in a post saying that they went to a restaurant or pub with them, or share a picture or comment about a group of friends.
Most of us will think about our friend’s feelings when sharing content about them on social media, but we don’t always know what will be important to them. The rules aren’t written down. Many of us will have had the experience of sharing something and then having a friend say “hi, do you mind deleting that post because of X…”.
Sometimes we listen to those objections and sometimes we don’t. Our friends might not be able to delete our Facebook content without our consent but their views are part of the complex set of things we think about when posting. They can unfriend us in real-life as well as on social media.
Adverse impact on other people
Beyond affecting a personal relationship there are many types of adverse impact that a Facebook post might have. Affecting copyright owners is one. Copyright has many many flaws but it is one of the ways societies help creators benefit from their work.

If I did own all the content I posted on Facebook then presumably I could post a picture created by someone else and start to make money off it by selling things. Money that could have gone to the artist.
I could, but I shouldn’t.
Both Facebook and I recognise that we need to abide by copyright legislation and that governments help enforce it. A copyright holder can complain directly to Facebook, or through the relevant national or international rules. The content is not mine to own to control and use how I wish. If I breach copyright in a way that unfairly impacts creators then fewer nice things get created. That would be bad.

Going deeper into adverse impact it could be that someone on Facebook posts something with the intent of causing harm.
To give just a few examples the content might libel someone, use hate speech, endorse terrorism, or use a sexual image of someone without their consent.
Facebook is a global service, and the legislation and definitions of those things will change from country to country, but in many countries those things would be illegal. A poster would lose control of the content, and perhaps even their liberty, as democratic governments use the powers given to them by people to stop the content from being seen and shared.
Facebook has its own moderation rules and tools that allow Facebook’s moderators to intervene proactively or for people to report content and get it removed. Again, that removal can happen without the poster’s consent. The poster is not in control.
Not all of the adverse impacts that moderation rules try to prevent are illegal and intentional. Others are unethical, or against social norms for a particular community or society. Moderation exists because the adverse impact from my posts might damage the health and goals of a community.
Moderation is not only done by Facebook and governments. Many community groups within Facebook have their own moderators and policies. Group moderators can also remove content without a poster’s consent.
Perhaps the moderators of sassy socialist memes or sassy libertarian memes will remove content I post in their groups if my content just ain’t sassy enough. The local Facebook group for the town I live in, like many other local Facebook groups, certainly has a fierce response to excessive advertising or outsiders criticising the town.
Other people can benefit from content
Shifting to a more positive, and less sassy, note people should also be aware of other people who can benefit from content they post. As the Financial Times recently noted “an explosion of [trustworthy data, such as that posted on Facebook] would give us the capability to understand our world in far more detail than ever before”. Facebook shares some of the data you post already so that other people can benefit, I think it should do more.
For example, Facebook users help maintain data about things like cafes, restaurants and leisure centres. We don’t only need this type of data in Facebook, we need it in many other parts of our lives, so Facebook have been exploring how to share data with the community-maintained OpenStreetMap. That will help everyone using the thousands of services that use OpenStreetMap. The Facebook users are not in control of this flow of data but they, and many other people, will benefit.

In other contexts then Facebook users might want to share content that they post with a third party that they trust.
The EU’s General Data Protection Regulations strengthens this want to a right, although it is a right with limitations.
I might decide to do this so that it benefits my local community, for example helping local government understand feelings on a particular topic, to help deliver another service I want to receive, for example by asking my friends if they want to join me on a a new photo-sharing service, or to help me learn things about my own behaviour and habits.
Unfortunately despite Facebook telling me that I can control how data is shared I can’t easily share that data with third parties.
Facebook allows people to download data they post, but it is not in a standard format and I can’t simply give another organisation that I trust the right to access it to the same extent that, say, the UK banking sector is starting to do.
The UK’s banking sector is expecting to see increased competition and new services as a result of making it easier for people to share data. Perhaps social media firms and the people who use their services would benefit from a similar collaborative effort to determine how to safely share data, which mostly includes other people, without creating adverse impacts.
It is good that Facebook is starting to share data to create benefits outside of their own service. They should do more of it by sharing carefully anonymised data openly, more sensitive data in secure conditions with researchers working for the public good, and by giving people ways to safely share data that they post with third parties that they trust.
Explaining this stuff is hard, but it is necessary
This stuff is complex and can be hard to explain in an accessible way, but it is necessary to understand the complexity before trying to make it simple.
Like many other types of content and data, Facebook posts and photos can be about more than one person. The content can create adverse impacts for those other people but it can also create benefits too. Because of this, users are not fully in control of the content they post, and they certainly don’t own it in the same way that we might own a house or car. Instead civil society, governments and service providers need to work together to design ways to help give people more control and to maximise the social and economic benefits, while minimising the adverse impacts.
Over-simplifying this necessary complexity risks us slipping into a world where instead individuals fully control the data that they create. That is the world that Facebook’s ad is describing to many people. How silly. That world will reduce the benefits and increase the risk of harms.
We don’t need more lengthy and unreadable terms and conditions but as the debate over data grows it would be helpful if major service providers like Facebook took greater responsibility in helping to create a more informed debate and helping people to make better decisions.