This is the (rough) text of a talk I gave at the British Computer Society (BCS) Location Information Specialist Group’s 3rd annual addressing update seminar in August 2016. There were more jokes in person. And some Pikachu. The slides for my talk are also online as are those for Ant Beck’s talk.
Hi, I’m Peter. I do some stuff at the Open Data Institute (ODI). The ODI was founded three years ago. It’s mission is to connect, equip and inspire people around the world to innovate with data. Its headquarters are in the UK but it works around the world.
I’m here to talk about open addresses in the UK. To understand the tale it’s useful to start off with a (shortened) bit of history.
Ancient history…
Addresses and other types of geospatial data were early targets for open data releases. They are vital datasets that make it possible to build many, many services and products. Way back in 2006 Charles Arthur and Michael Cross wrote in the Guardian to ask the UK government to “give us back our crown jewels”. They pointed out the complex arrangements for maintaining address data and how the data was sold to fund those complex arrangements. They even pointed out the issues it generated for the 2001 census.
In 2009 the UK government announced that Tim Berners-Lee, one of the ODI’s founders, was going to help it open up data and in 2010 government said that postcodes and address data were going to be early releases. Victory!

But it was a pyrrhic victory. Whilst government released many thousands of datasets the promised address data was not one of them. In 2013 the Royal Mail was privatised along with its rights to help create and sell that address data. The complex arrangements that were pointed out in 2006 just got more complex. And, in the meantime, another census happened with the inevitable, and costly, need to build another new address list.
The open data community was rightly sad, and probably got a bit angry. They knew how important that data was. They kept working to make things better. They didn’t just tweet, they organised.
More recent history…
In 2014 the Cabinet Office’s release of data fund provided some money to the ODI to explore whether it was possible to rebuild the UK’s address list and publish it as open data. The ODI pulled together lots of people who work with addresses to share and debate ideas.

This led to the launch of Open Addresses UK. I was one of the team working for Open Addresses. We worked as openly as possible with regular blogs and open source code.
We explored the benefits of better address data for the UK. We found that we could help fix problems such as the months it can take before new addresses are added to computer systems across the country. Months during which someone might not be able to order a pizza, get home insurance or register to vote. We looked at the economic evidence from case studies of other countries, such as Denmark, that have released address data as open data. If the success of Denmark scaled in proportion to the population of the country then the UK could expect to see an extra £110 million a year of social and economic value. Value that we don’t get at the moment because paid data creates less economic value than open data.
We looked at funding models. We started off with £383k of funding from the Cabinet Office. We got some extra funding from BCS (thank you). We knew that we would need to be able to show people what our services would look like before we could start bringing in funding from the users of address services.
From talking with potential users of those services we learnt about the challenges of address entry on many websites. User research supported our theory that moving to free-format address entry would both make life easier for many people and lead to better quality address data going into organisations. We built a working demo of that service.
We knew we needed to gather address data. Following on from the discovery phase we built a model that would allow any organisation or individual to contribute their own address data; that would allow anyone to add large sets of open data containing addresses if they followed guidelines and confirmed that they were legally allowed to publish that address data as open data; and put in place a takedown policy to investigate and remove any infringing data. For the legally minded, we were set up to host the data. This was important. In the past people had been threatened with legal action by the Royal Mail over address data and the hosting model provided a defence.
Unfortunately we hit a snag.

We learned that one of the largest open data sets held by government was tainted by what we called ‘digital cholera’. It contained third party rights that government was not authorised to licence as open data. This was no good. We wanted to publish address data that was safe to use.
We didn’t want to spend the limited grant funding on more and more legal advice or court battles (sorry lawyers…). So we concentrated on other approaches.
We used clean open data sets and statistical techniques to multiply the address data we already had. For example, “if house number 1 exists and house number 5 exists then house number 3 probably exists”.
We started developing a collaborative maintenance model. People could use our address services to both improve their own services and improve the address data that everyone was using. The model would enable us to learn and publish new address information (such as alternative addresses — like Rose Cottage rather than 8 Acacia Avenue and new addresses) as people started to use them. This would increase the speed of publishing new information and improve data quality. By crowdsourcing data through APIs the data would get better as more people used it.
The team recognised that these new ways of collecting address data would impact on confidence. So, we started developing a model that would allow the platform to declare a level of confidence in each address. The model allowed for different levels of trust based on how frequently we’d seen an address, who reported it, and how long ago they’d reported it. Data users could use the APIs to determine confidence and choose whether to trust an address for their particular use case.
But all this time the clock was ticking. There was limited funding. From the beginning we knew that we were testing two hypotheses.

Unfortunately we discovered that both hypotheses were true. We could build much better address services using modern approaches, but the intellectual property issues would keep hindering us.
A report was published: to share the lessons of what worked, and what didn’t. As you’ll see in the report even with all of our mitigations against intellectual property violations in place, Open Addresses was only able to find one insurer who would provide it with cover for defence against Intellectual Property infringement claims. The insurers were too concerned that the Royal Mail would take legal action to protect their revenues from address data.
A blog was published about the shades of grey in open data. And then Open Addresses went to sleep.
Someone else would have to take up the challenge of opening up address data and making things better for everyone.
Meanwhile…
While Open Addresses was happening so were other things. Lots of things. I’m obviously interested in the data ones.
The ODI was thinking about who owned our data infrastructure. Data is infrastructure to a modern society. Just like roads. Roads help us navigate to a location. Data helps us make a decision.
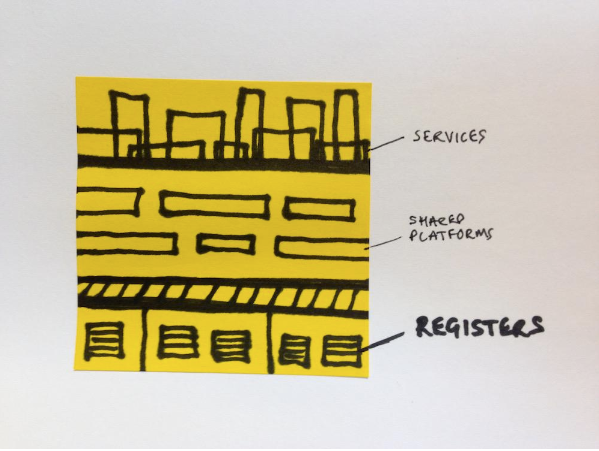
The government was also working on its policy of government-as-a-platform. Companies House were opening up their data and putting it on the web. The Land Registry described itself as a steel thread that we could all build on.
Things started to come together with the description of registers as authoritative list that we could all trust. We could all build things on top of government’s open registers.
Registers are data infrastructure. An important part of data infrastructure is geospatial data, like addresses.
Now
In the 2016 budget it was announced that government had allocated £5m to explore options to open up address data.
It is important to understand that this is about exploring options. As Open Addresses had learnt UK addresses are pretty complex. We have centuries of legacy to deal with.
Matt Hancock, who was the Minister for the Cabinet Office when the announcement was made, likened it to the ‘US administration (decision) to allow GPS data to be made freely available for civilian use in the 1980s, which he said had “kick-started a multi-billion dollar proliferation of digital goods and services”’.
He got the importance of this data being open. Not that surprising when you know that his parents ran a company that built “software that allows you to type your postcode into the internet and bring up your address”.

Government is exploring the options as openly as possible. They are sharing their research into topics such as the need and complexity of address matching. and the need for a common language for addresses. They are trialling technology approaches, you can see the source code for yourself: it’s open. And this all forms part of the bigger picture of building registers as infrastructure for the government-as-a-platform strategy. In fact just this week government announced an early version of an authoritative register for English local authorities.
Whilst not all of the work is in the open (remember, the arrangements for UK address data are complex commercially and legally) it is clear that many government organisations — such as the Cabinet Office, Ordnance Survey, BEIS and Treasury — are working together to explore the options and business case for an open register. Good ☺
Will the address wars ever end?
All of the above is what I said in the talk at the BCS addressing update seminar. At the end the audience debated some of the issues raised. The legal issues seemed to confuse some people — derived database rights are tricky. Eventually I was asked the most important question: will this new UK government initiative to create an open address register succeed?
The honest answer is “I don’t know” but I do trust the people working on it. They are good and there is clear political will to get this problem sorted. With good people and political support it’s possible to do hard things. I choose to be optimistic. I think they’ll succeed. Good ☺
It is important for the UK that they do. We need to build for the future web of data.
Other countries recognise the value of data infrastructure that is as open as possible. The USA, Australia and France have all recently made strong moves to get their address data open.
Data infrastructure is a competitive advantage in the 21st century. We need to move on from old licensing and funding models that don’t make the best use of the qualities of the web and data.
Let’s build better data infrastructure that makes things better for everyone.



Hacker Noon is how hackers start their afternoons. We’re a part of the @AMI family. We are now accepting submissions and happy to discuss advertising & sponsorship opportunities.
If you enjoyed this story, we recommend reading our latest tech stories and trending tech stories. Until next time, don’t take the realities of the world for granted!

0 Comments
1 Pingback