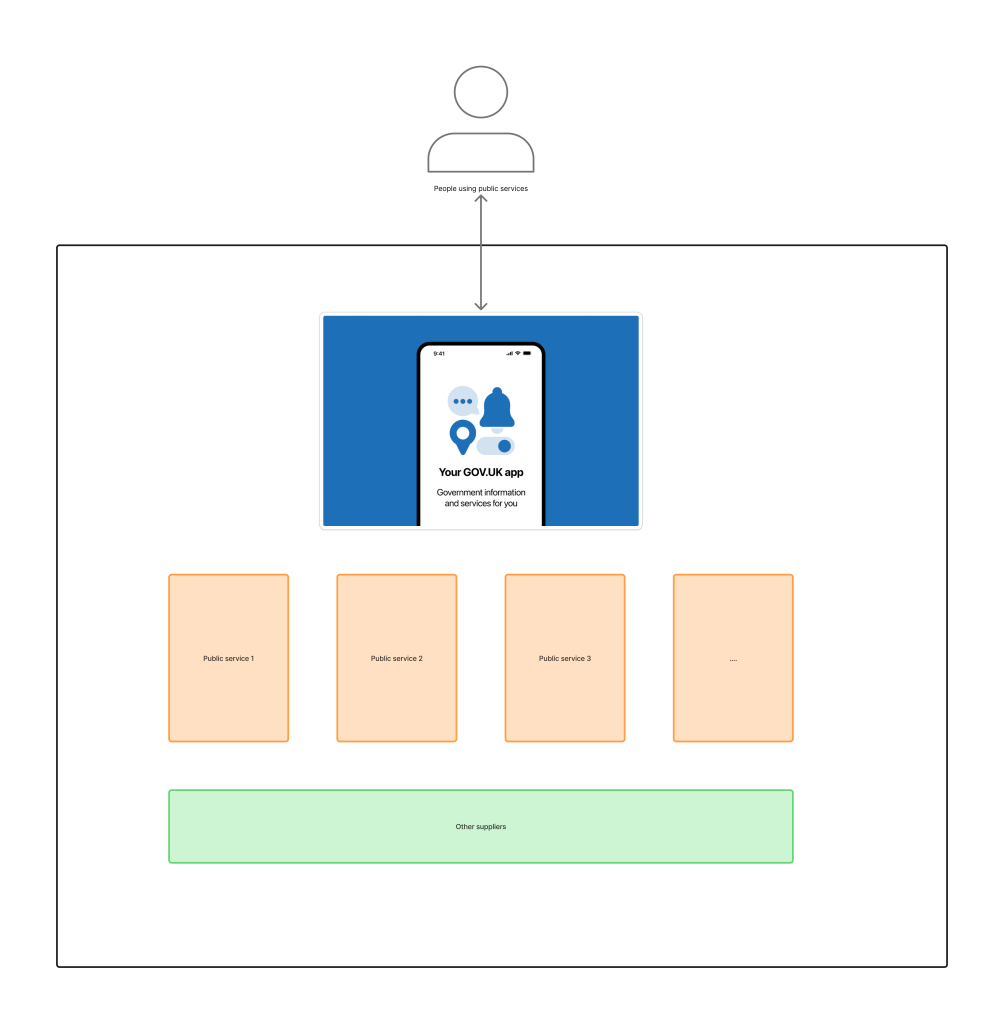
The app is intended to provide another way to access public services alongside other places like job centres, town halls, schools, telephone call centres and the gov.uk website.
Ideally people will be able to choose what route to use based on what works for them, the friends and family they help to access public services, and the particular services they need at the time they need them.
In the circles I work in there’s been lots of discussion of the app
One thing I’ve not seen mentioned is that the app tries to avoid legal responsibility for providing a decent public service to people. It even recommends that people take separate professional advice rather than relying on the services and information provided by the GOV.UK app.
It would improve public services across the sector if the app took more responsibility and encouraged other public services to do the same.
we do not provide any express or implied guarantees, conditions or warranties that the information available via the GOV.UK app will be:
+ suitable for your individual requirements + available + current + accurate
So, the government is unwilling to say that public service information provided by the government is accurate?
We do not publish advice on the GOV.UK app. You should get professional or specialist advice before doing anything on the basis of the content [published on the app].
So, if I used the app to look for government advice on how to get a UK driving licence then I should also speak with a lawyer before applying to the government?
we’re not liable for any loss or damage that may come from using the GOV.UK app. This includes, but is not limited to, the loss of your:
+ income or revenue + salary, benefits or other payments + business ..[there’s more]
So, if I used the app to sort out something to do with my parent’s pension, there was a mistake in the app and my parent lost their pension then the government would not help me or them out?
Seriously?
How do things like this happen?
There’s a few things that could have led to this kind of disclaimer being added to the app. For example:
GDS might worry about taking responsibility for other public sector organisations. Even in its beta stage the app includes bits of public services provided by multiple public sector organisations. Perhaps GDS didn’t want to be held responsible for other organisation’s mistakes? Or even to be responsible for working out who is responsible? But part of the app’s job is to help people understand and deal with the many public sector organisations within it. Not to try to shift responsibility around and leave it to the public to work out how to hold organisations who fail them accountable for those failures.
Traditionally gov.uk has focussed on information. The proposition says that gov.uk does not offer advice on what the user should do, unless users need advice in order to complete their task. The app is due to have a chatbot, called GOV.UK Chat, added to it and chatbots can both add more complex supply chains and provide information in ways that more users will experience as advice. GDS may also be nervous about AI chatbots’ susceptibility to technical malfunctions, like ‘hallucinations’. But, let’s be honest, the point when information becomes advice has never been a clear one and as GDS’s AI playbook says “Ultimately, responsibility for any output or decision made or supported by an AI system always rests with the public organisation”. Sound advice.
When does information become advice?
GDS aren’t used to delivering apps and apps often have terms and conditions. GDS’s One Login app has a similarly strong disclaimer and says there is no liability for “loss or damage arising from an inability to access or use GOV.UK One Login“. Hardly a reassuring statement when millions of people will need to use One Login to get access to things like tax payments, state pensions, disability and unemployment benefits. One Login has already had at least one serious security vulnerability. Who will be liable if, or when, a hacker takes advantage of the next one?
Lawyers gonna be lawyers. It’s easy to imagine some lawyers recommending these kinds of terms and conditions, and people managing the app deciding they need to follow that advice rather than challenge it. If you look then you find that since 2013gov.uk has also had a set of terms and conditions that don’t guarantee the government will provide accurate information and tell people to read the terms and conditions of all the public services they access through gov.uk. It’s important to support people to understand how public services work, but you can’t do that in a set of legal terms and conditions. Yuck.
The app should encourage the public sector to take more responsibility
GDS is not providing a commercial service that can hide behind contracts and lengthy terms and conditions. In the private sector you find backstop compensation schemes – like the Financial Services Compensation Scheme – when organisations fail. There is no equivalent for public services and, to put it politely, the UK government does not have a great record of runningcompensationschemes for its failures.
Instead the backstop for responsibility is ultimately things like administrative law and politics.
Would the app’s Ministers really want to stand up in Parliament and say that the app does not provide accurate information? That people should pay for professional advice after reading advice provided by the government? That the government isn’t liable for its own mistakes?
Not quite the vision being sold by Peter Kyle, and DSIT’s blueprint for a modern government, of more public services that work across institutional boundaries and do the hard work to make things simpler for people.
So, if government lawyers are the ones recommending contractual terms and conditions then both GDS team and its Ministers should say no.
By taking clear, legal responsibility at the app level, and tidying up responsibility on gov.uk too…, GDS can encourage other public sector organisations and their suppliers to take responsibility for providing better public services by making clear their actual legal and democratic responsibilities and ensuring they have clear liability before their services are made available.
The GOV.UK app can shape an ecosystem of other services and suppliers to take responsibility for providing better public services to people.
Given the government’s push on using more automation and technology clear responsibilities and liabilities will only become more important. It might reduce the chance of the government having to create more compensation schemes that can cost billions of pounds.
A culture of responsibility across the public sector would mean that more public services work for people, and fewer public services that fail the people they serve.
When I work within teams, talk with people and read policy and strategy documents, particularly around the UK public sector, I find it useful to quickly align on what people mean by some words so that we can get stuff done. “Digital” is one of those words.
Many words have multiple meanings. Words can gain and lose those meanings over time as us humans do one of our human things and try to communicate concepts to each other.
Originally a Latin word for fingers and toes, “digital” became part of the phrase “digital computer” when electronic computers were invented in the 20th century.
But digital has acquired several more meanings in the last few decades.
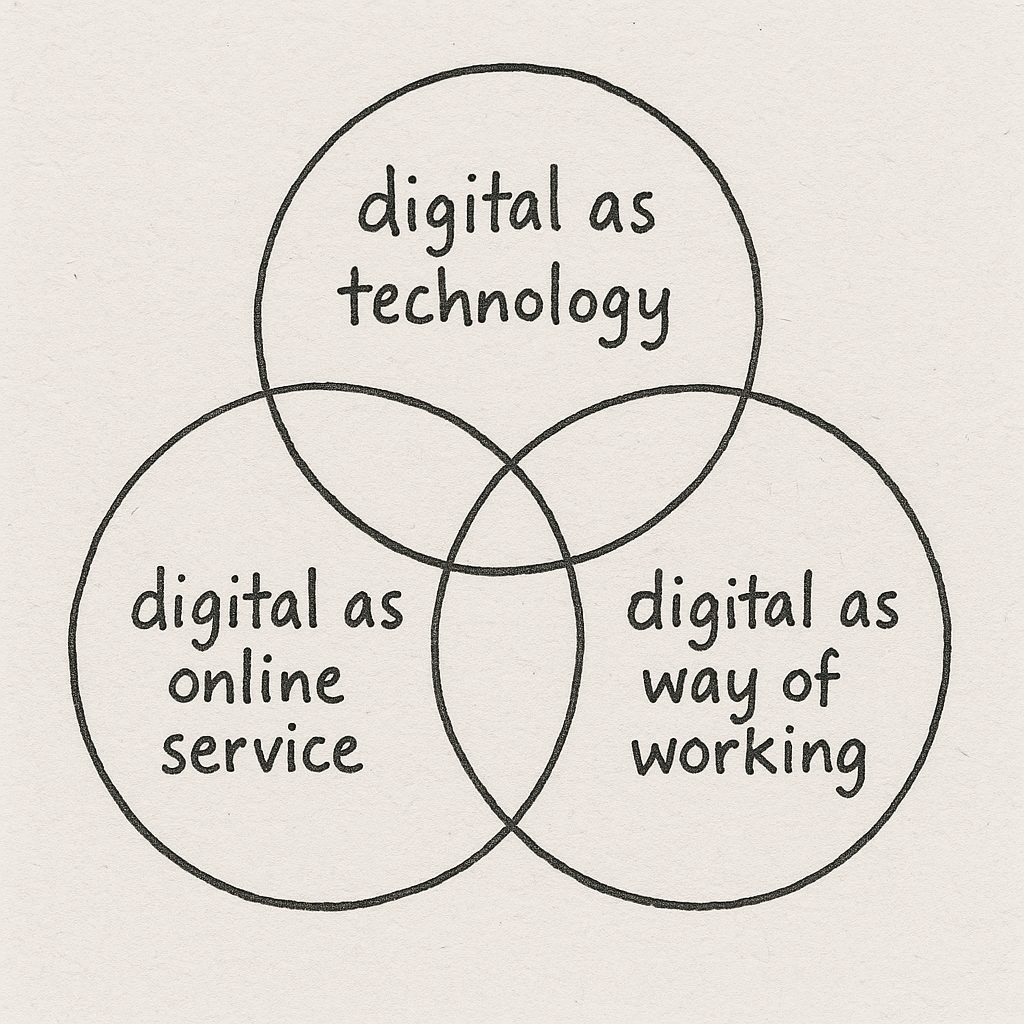
When I ask people what they mean by it there’s different definitions that I regularly hear in the world of digital government policy and public services:
Digital as a type of technology
Digital as an online service
Digital as a way of working
Image drawn by chatGPT as my handwriting is mostly illegible, my drawing is worse and I didn’t want an image that looked too formal. (NB: like most Venn diagrams, the centre is not necessarily a thing to aim for…)
Sometimes these meanings get combined, which can be confusing. I find that disentangling them is useful.
Obviously ‘digital’ is not the only word which gets tangled up in this way, but given its importance it’s a useful one to align on.
1. Digital as a type of technology
Digital can be used to describe any technology related to electronic computers.
This was part of what was happening with the term ‘digital computer’. The original ‘computers’ were humans who added up numbers, it was the addition of technology that made the original computers ‘digital’.
A roomful of human ‘computers’, courtesy of the US Library of Congress. Note how they are all female. Programmed Inequality is a good read on the history of women and digital computers in the UK.
You see this definition used in terms like the ‘digital revolution’ – to indicate the changes happening as the world adapts to computers, internet and the web – or ‘digital infrastructure’ to talk about telecoms infrastructure and data centres.
Implicitly this definition can exclude other forms of technology like physical machinery, roads, wheels, and paper.
2. Digital as an online service
The second usage is digital to mean online services that are only available over the internet or web. It might even be something that only works on a smartphone, like an app. I’m not sure how or why we’ve ended up calling these ‘digital services’ rather than ‘online services’.
Facebook is often called a “digital service” or Google a “digital company”. The UK has a Digital Regulation Cooperation Forum (DRCF) whose purpose is to “deliver a coherent approach to digital regulation for the benefit of people and businesses online” for regulating these kinds of services and companies.
While Facebook/Meta and Google obviously exist in the physical world – just think about one of their many offices, data centres, undersea cables or the tens of thousands of people who work to moderate content – when people talk about their ‘digital services’ they tend to think about the bits that are only visible online.
If you work in similar places to me you don’t need another image of a ‘digital service’, so here’s a GIF of a scary rabbit chasing a cat instead
Similarly the term ‘digital service’ can be used in digital government circles to mean the bits of a public service that are interacted with over the internet and web.
An online service like this is rarely the entirety of a public service – there are many reasons why governments can’t just build websites and apps – but they have become an increasingly important and visible part of public services.
I say rarely, because sometimes governments can reasonably decide that a service will only be accessed online, but there are limits. For example it might be appropriate to require large businesses to pay taxes online but it would be inappropriate to require individuals to pay taxes online unless there was a larger service that provided support to enable everyone to do it.
3. Digital as a way of working
Third, there’s digital as a way of working.
Tom Loosemore of Public Digital talks about digital as ‘applying the culture, processes, business models and technologies of the internet-era’ which is a pretty good description.
No, I’m not going to try and further define digital as a way of working. So, courtesy of Wikimedia, here’s a picture of a roughly organised wall of post-it notes as a way of getting it across.
It emphasises things that are not only technology and indicates that ‘digital as a way of working’ can be used to improve not only ‘digital as online services’ but also a wider set of services and institutions.
Some people take this kind of definition further to talk about who or what ‘digital’ is for. For example Public Digital’s description talks about using digital ways of working “to respond to people’s raised expectations”. I don’t think everyone has raised expectations.
I tend to encourage teams to decide their purpose in their context.
If the context is delivering general public services then the purpose might be “to meet everyone’s needs”, if the context is tackling issues caused by lack of trust then the purpose might be “to deliver trustworthy services”, etcetera, etcetera, etc.
The definitions can get combined
Finally, it’s important to be aware that many people combine the definitions.
Perhaps they’re using digital ways of working and digital technologies to deliver a digital service. Or perhaps it’s a policy or strategy paper where someone has liberally sprinkled the word digital into all sorts of places in the hope it will make the organisation look modern. Perhaps they’ve invented a wholly new definition, *gulp*.
This young man likes digital
Sometimes I even find people that don’t even realise that they’re limiting the potential usefulness of their modern ways of working by only applying it to computer technologies and only to bits of services that are visible online on the web and internet. That they’ve ended up accidentally prioritising a subset of the population and the method they need to use to access public services.
So, separating out the different meanings of the word digital can reduce confusion and enable teams to meet a larger set of needs.
Digital is not the only word that has multiple meanings
And finally. Obviously digital is not the only word that can be loaded with multiple meanings. Just try asking people what they mean by terms like ‘AI’, ‘product”, ‘policy’, ‘personalisation’ or ‘digital identity’ if you really want to have my kind of ‘fun’.
But ‘digital’ is one of the key ones and there’s at least three definitions regularly in use. Understanding what other people mean by it and aligning on a common meaning can be a useful thing to do.
The UK has an official list of building addresses and their locations – ‘address data’. This data is a vital resource for building public and private services that rely on locations, and is part of our national data infrastructure. At the moment, the UK’s address data is expensive, hard to access, not always accurate, and hard to correct. This causes problems for businesses and other organisations that rely on address data – and ultimately it affects us all.
The debate had contributions from Labour, Liberal Democrat, Green and Conservative backbenchers. The Minister for the Conservative government then rejected the amendment.
Reading and watching back the debate made think about three things:
The government agreed to share deeper analysis, which is good news
But it misunderstands why previous attempts to recreate UK address file failed, that is bad news – and not just for addresses
The risks of openly publishing address data, or of not publishing it, are misunderstood
The government agreed to share deeper analysis
The Minister said that they were “very happy to share deeper analysis” of address data. This is good news, both because better evidence can create a better debate but also as it indicates that the government actually has some analysis.
The Geospatial Commission said they had no analysis
In 2022 the Geospatial Commission responded to a Freedom of Information (FOI) request by saying that it did not assess address data when preparing its strategy. Similarly in 2023, when the Geospatial Commission was agreeing a £31m contract with the Royal Mail, they said that they did not perform any analysis of the costs, benefits or alternative options.
There were some previous projects that did do deeper work. For example, in 2017 the government spent £500k, out of a potential budget of £5m, investigating how to create an open address file.
A map of open address data around the world from OpenAddresses.io
A misunderstanding of why previous attempts to recreate UK address data failed
The Minister referred to previous attempts to recreate the UK’s address data, saying
“the resulting dataset had, I am afraid, critical quality issues”.
Viscount camrose
As someone who spent part of 2014/15 working on a project to recreate the UK’s address data that was not why our project was stopped. The Minister might want to ask officials for more details as we learned some interesting lessons that the government needs to learn too.
The kind of innovation that government policy wanted to support
Our approach to recreating the UK’s address data was to start with data that the UK government already publishes. In line with the government’s “open by default” data policy, organisations like the Land Registry, Companies House, and the Valuation Office Agency spend money to make the data they hold available for other people to use. Some of this data contains address information.
We intended to make the bulk data available for free, and then generate just enough revenue for sustainability – perhaps from high volume users of the API. We set ourselves up as a not-for-profit company.
It was the kind of innovation that the government’s open by default policy is intended to support.
Much of the government’s open data was not ‘open’, this creates legal risks
Unfortunately we found that much of the government’s open data was not actually ‘open’.
The government’s copyright licence (the Open Government Licence, or OGL) excludes third party intellectual property rights. The third parties who hold IP rights in address data, Royal Mail and the Ordnance Survey, are litigious and many of the government organisations that published the data were unable to be clear on whether or not there was Royal Mail or Ordnance Survey rights in the data they published. We only used datasets where the publishing organisation told us it was ‘safe’.
But even though it was government organisations publishing the data they would not be liable if there was a legal issue. We would be. So we needed insurance cover.
But given the risks only one insurance company was willing to offer cover and that was on unrealistic terms. So, we stopped the project.
To put it another way, an innovative, not-for-profit business could not use the data that multiple government organisations published to support innovation, because another government organisation might take legal action.
There are new plans to publish more government data, they risk the same problems
Zooming forward in time from the ancient history of 2014/15 and back to the present day various UK government departments are currently making new plans to publish more government data.
This is because of initiatives like the Vallance report on pro-innovation regulation of technologies and a desire to support the UK’s AI industry. High-quality, authoritative government reference data is one way of reducing the hallucinations that the current generation of AI models suffer from. Sounds sensible, right?
But publishing widely used address data is a lot simpler and safer than much of the planned work, yet the government failed to do so in a way that allowed organisations to clearly understand what they legally could, or couldn’t, do with it. Will this new wave of government data come with instructions telling AI models and engineers not to do anything with addresses? And what other third party rights might be lurking in there? Or will government just make AI’s copyright issues even more complicated.
If the government does not understand why its previous attempts to publish data did not yield the desired benefits then I fear a lot more wasted money in the future.
The risks of openly publishing address data are misunderstood
In the debate Lord Bassam said
“there is a balance to be struck between privacy issues and the need to ensure that service delivery and commercial activity operate on a level playing field”
LORD BASSAM
It is good that politicians consider privacy issues, but this misunderstands the risks.
Address data does not create new privacy risks
The list of addresses does not tell us where specific individuals live, the only personal data involved is likely to be those of people who name their business address after themselves. Instead address data tells us where people might live, work and play but not who is living, working or playing there.
(As an aside: I don’t want to imply that there are no risks of privacy, or other human rights, breaches with non-personal geographic data. For example in a separatist war in Sudan in 2011 atrocities were carried out because satellite data showed where particular groups of people were. But, hopefully, the UK is a long way from a separatist war and, let’s be honest, truly harmful actors will either simply buy the address data or use an illegal copy.)
The harms created by the lack of access to address data are more pressing
By contrast Lord Clement-Jones pointed out that
“The harms created by the lack of access to address data are more pressing”
LORD CLEMENT-JONEs
While Baroness Harding pointed at the issues with the current data quality saying:
“the quality of the data is not good enough….Anybody who has tried to build a service that delivers things to human beings in the physical world knows that errors in the database can cause huge problems. It might not feel like a huge problem if it concerns your latest Amazon delivery but, if it concerns the urgent dispatch of an ambulance, it is life and death.“
BARONNESS HARDING
Elsewhere the National Audit Office has pointed to the challenges of creating and using the shielding list of people with extreme clinical vulnerabilities during the pandemic. One of the challenges was inconsistent address data in different formats in different IT systems and organisations. This is one of the many challenges that opening up the official list of address data will help with, because over time more organisations will refer to and use the same reference data.
If the funding model changes then will quality drop?
There is one risk that was not discussed in the debate though.
If the maintenance and publication of address data is not funded from licence fees collected by Royal Mail and Ordnance Survey then will the quality drop?
This is where there is an important balance to be struck as people and organisations need the correct incentives to publish useful data.
Bluntly, this is the risk I worry about the most. Money is only one type of incentive but it is an important one in this context and it is one of the reasons why I’m so keen to see some deeper analysis of the current costs.
Experience tells me that the current costs are significantly overstated – particularly the Royal Mail who claim costs of ~£25m/year for ~300,000 changes/year. But however much the costs can be reduced it will still cost money to publish quality address data.
Making the publication of the data a statutory duty, as this amendment would have done, is one way to help tackle this risk. It requires the government to fund and do the work.
Perhaps the money might come from general taxation, and the increase in economic activity that will come from publishing the data? Or perhaps from a small increase in registration fees collected by local authorities who do most of the work to create addresses? Or a small increase in the Land Registry transaction fees, after all they handle nearly 50 million transactions per year?
Other countries have changed legacy business models, the UK should too
Whatever the final decision it will need some coordination and activity from a few public bodies willing and able to work together to publish address data as a public service.
And that’s where I hope the government is really focussing its analysis. Not on whether to publish address data for free, but on how to do it.
Because in the 21st century it is pretty sensible for high-income countries to make reference data, like addresses, as widely available as possible. That is why peers from so many different parties supported this amendment, and why so many other countries are doing the work.
The hard part of the work is changing the legacy business models and incentives of government organisations so that they make it happen. Other countries have done that, and it’s long past time for the UK to do the same.
The UK is having a general election on December 12th. Over the next week political parties will put out their manifestos. Those manifestos will contain lots of commitments about what the parties will do if they are elected.
When I looked at the manifestos for the last general election in 2017 I was disappointed at their lack of recognition of the changes the world was going through because of technology. To help this time, here are three simple tech policy ideas for any party. They’re focussed on helping the UK adapt to the current wave of technology change. They are a bit late for the manifestos, but they still might be useful.
A bit of context
First, a bit of context. Technology is always changing but it has changed a lot in the last few decades with the proliferation of computers, the internet, the web, and data. These technologies have changed things for governments.
Some citizens now have higher expectations from public services. They expect public services to behave like those they get from Google, Amazon or whichever service is hot this year, *checks notes*, such as ByteDance’s TikTok. Technology is enabling things that some may think should be public services — like accurate mapping data on smartphones, or being able to have a video call with a doctor.
Other citizens now have more fear. Perhaps because they are excluded from those services because they lack skills or access to the internet or perhaps they are at risk of being discriminated against because technology is being used to perpetuate, or accentuate, existing societal biases.
Using new technology to help deliver public services that work for everyone is a tough job that, despite good work by Government Digital Services, government still has not cracked.
New technology has also enabled new businesses, markets and types of services to emerge. Things like smartphones, social media, cloud computing, online retailers, online advertising, and the “sharing economy”. The world is now more interconnected. Someone in Wales can rapidly build an online service and start selling it to people in India, and vice versa. Meanwhile because the technologies have also been adopted by existing companies they affect government’s role in existing markets.
Technological waves of change like this are not new — I recommend reading some history about the after-effects of the invention of ocean sailing, printing, electricity, or television — but governments have been particularly slow to adapt to this wave of technological change.
Why? Perhaps because the technologies have changed things globally. Perhaps because of the type of governments that we have had. Perhaps because of lobbying by businesses. Who knows. Future historians will be better placed to assess this.
Anyway, my suggestions are not about the details of each of these areas. Instead they are about how to increase the rate of adaptation for the next government. About how to get more radical change.
Political parties should start with themselves. They need to be open about how they are using data and online advertising and publish data about their candidates to help voters make more informed decisions. Political parties should not use micro-targeted advertising during the election, and should challenge their opposition to follow their lead. Where necessary they should err on the side of caution when using advertising tools. After all, much targeted advertising is already likely to be illegal under existing legislation. Doing these things will help politicians learn how to responsibly use technology while competing for power. That will help them use technology responsibly if they get in to power.
Whoever gets into power should then ban targeted political advertising until it is shown to be reasonably safe. To understand the effects researchers will need access to data held by the big technology platforms like Facebook, Twitter, Google and Apple. Organisations in the USA have faced challenges when trying to do this with Facebook but approaches like the ONS ‘five safes’ and the Ministry of Justice data lab show that parts of the public sector have the necessary skills to design ways to do it. Government should use models like this to give accredited researchers access to data held by the platforms to inform future policy decisions and, perhaps, when to relax the ban for certain kinds of ads.
Develop technology literacy in more of the public sector
Sometimes a horrified face emerges from behind my polite face. I apologise to everyone who has seen it.
Unfortunately too many people still do not get it. In my own meetings with governments I am often surprised, and sometimes horrified, by whole teams of people with limited technology literacy making significant decisions about technology. (Similarly, I am often surprised, and sometimes horrified, by teams of technology experts making significant decisions that impact on policy or operations with no real experience in those areas.)
Not every public sector worker needs to be a technology expert, and it is certainly not true that everyone needs to know how to code, but it is necessary to have technology literacy in many more parts of government. More public sector workers need to understand both the benefits and the limitations of new technology and the techniques that people, like me, use to build it.
This is one of the most important things to focus on. Different skills are needed by different roles, but an underlying element of technology literacy is useful for everyone.
To start providing this technology literacy I would recommend vocally demonstrating that technology experience is as valued as other skill sets and encouraging more technology experts to join teams that lack that experience, and by seconding non-technology staff into technology teams. In both cases people can then listen to and learn from each other.
An independent inquiry into technology regulation
Finally, regulation. Technological change needs changes to regulators and can lead to the need for new ones. There are a growing number of known gaps in technology regulation. Some of these gaps affect public services, like the police. Others affect public spaces, like facial recognition. Some affect new services like social media. Others existing ones, like insurance. In some cases it is not clear if regulators are appropriately enforcing existing rules, like equalities and data protection legislation, while there will be a large number of gaps that people simply haven’t spotted yet.
Previous governments have set in process various initiatives such as considering the need for a new social media regulator, a national data strategy, and a Centre for Data Ethics and Innovation (CDEI), but these initiatives are not adequate. They are controlled and appointed by the current politicians, operate within current civil service structures, and are mostly taking place in London. The changes bought about by technology are too fundamental for this approach to work. The UK needs something more strategic, more radical, more independent, and more citizen-facing.
An independent inquiry into technology regulation should be set up. It should have representatives from around the UK; with different political views; with experience from the public sector, private sector and civil society; and from both citizens that love modern technology and from the groups that are most at risk of discrimination. It should look across the whole technology landscape, have the power to call witnesses, and be empowered to make a series of recommendations for changes to legislation and regulation to help set the UK on a better path for the next decade.
Inquiries like this can happen faster than you think. The recent German Data Ethics Commission took just 12 months to come up with a set of excellent recommendations. Setting a similar timescale for an inquiry in the UK will allow the next Parliament and the next Government to focus on delivery.
It is necessary and possible for the UK to adapt to technology faster
Politicians and their teams can learn how to use technology more responsibly by tackling the fear around technology and politics; mixing up teams in the public sector can help staff learn from each other; and an independent inquiry into technology regulation can help set the UK on a better path to the future.
The UK needs to adapt to technology faster. For the good of everyone in the UK, but particularly those who are being disadvantaged by irresponsible use of technology, can we do it? Please?
A picture of some people by L S Lowry (via Flickr)
The committee is currently investigating Artificial Intelligence and whether the existing frameworks and regulations are sufficient to ensure that high standards of conduct are upheld as technologically assisted decision-making is adopted more widely across the public sector.
Big topic. After all AI is a range of techniques that uses people, mathematics, software and data to make guesses at the answer to things. It can help, and hinder, with lots of the huge array of things that the public sector does.
I represented the Open Data Institute (ODI) on a roundtable for this investigation. A couple of people have asked me what the roundtable was like and what I said. Here’s a quick blogpost.
Preparing for a roundtable
The ODI team get invited to lots of roundtables and events. We decide which ones to do and who does them based on a range of criteria. The invitation for this one went to our CEO, Jeni Tennison, she passed it to me to do. My goal was to help the committee, learn from what other attendees were saying, and test some of our ideas in front of this audience.
We did our usual preparation by sharing the questions around the team in the office and telling our network that we were going along to hear what advice they gave us. That technique provides a lot of input. It also helps me represent the ODI and the ODI’s network, rather than simply myself and my own views.
I summarised it down to a few key points to try and make, and then tried not to over-prepare. Over-preparation is the worst sin: it makes me sound even duller than normal.
Rounding a table
The roundtable itself was at Imperial College in London.
The setup was more informal and the committee was more friendly and asked more insightful questions than most similar things I’ve done. That was good. My background is technical and private sector — I previously spent 20 years working with telecoms operators building products, systems and networks — so I always worry that I’ll misunderstand or miscommunicate particular words or phrases. That would damage both me and the organisation I represent.
Anyway, I managed to get over versions of some of things that we’d prepared and/or that we regularly discuss in the office and that were relevant to how the roundtable took shape:
that there is little transparency over use of AI in the public sector and of how the UK government’s Data Ethics Framework is being used. I know that there is good and bad work being done, but mostly because I know some of the people doing it. How are the general public meant to know?
that we need to focus more on the people who design, build and buy AI services. Exploring what responsibility and accountability they should have and how we give them the space, time and money to design those services so that they support democracy, openness, transparency and accountability as well as being efficient and easy to use
that the current focus on ethical principles and AI principles do not seem to be having a usefuleffect. That instead we need to couple those top-down interventions with more bottom-up practical tools (like the framework or ODI’s Data Ethics Canvas) and more research into how the people designing, building or buying AI systems make decisions and what will influence them to comply with the law and think about the ethical implications of their actions
that control, distribution of benefits and harms, rights and responsibilities about AI models would be a useful area to explore
that eliminating bias is the wrong goal. Bias exists in our society, some of that bias becomes encoded in data and technology. AI relies on the past to predict the future, but the past might not reflect the present let alone the world we want. We should build systems that take us towards the future we want, and that can adapt as things change
I also learnt a lot from other attendees with some interesting things for myself and the team back in the office to chew over.
After the roundtable
A couple of weeks after the roundtable I was sent the transcript to review. The committee will publish that transcript openly — which is good and healthy. Attendees get to see the transcript first so they can suggest corrections to simple grammatical errors or transcription problems. That’s why I’m not commenting on or sharing what other people said.
It is important to review the transcript. There are sometimes errors. For example, in this transcript I was recorded as saying that my boss, Jeni, was “whiter than me” rather than “wiser than me”. I have no idea how I’d measure the former but I certainly know that she’s the latter. Some of the words and thoughts in this blogpost come from Jeni and others in the team like Olivier, Miranda, Renate, Jack &c &c &c.
Reading the transcript also helps me understand the difference between the clarity of my speech and the clarity of my writing. I’ve left most of my spoken errors in place. Just like the state we can’t only communicate in words and pictures that are sent through a computer. Most of us need to get better at speaking with humans.
I was home recently and took my sister’s dog for a walk. When we were young we had dogs, Spud and Gyp, so it was a walk I’d taken before. A few things had changed. One was that there was less dog poo.
Me (left) taking my sister’s dog for a walk around Fairhaven Lake.
It was strange comparing the memories of those messy streets, including muck left behind by Spud, to the reality of the present day with dog walkers cleaning up and signs warning of penalties if they did not. There has been a change in our social norms. In return for the right to walk a dog, most people now accepted they needed to clear up behind them.
My day job is doing policy for the Open Data Institute. Policy is about changing outcomes, hopefully for the better.
On their own, legislation and guidance won’t fix challenges like data ethics, making data as openly available as possible, or the many other complex challenges that limit the social and economic value that societies get from data. It will need social change too.
I’m interested in how that change happens, including how society decided dog walkers should clean up the dunghills created by dogs.
People like having dogs, but dogs make a lot of shit
It would take a lot of rain to clean up 500,000 pounds of dog feces. (image Taxi Driver, copyright a big film company)
People like having dogs (*). They like having a companion. They like going for walks. Dogs can make people feel safer, particularly in a city that had as high a crime rate as 1970s New York. But dogs make a lot of shit (**).
In 1974 New York City’s Bureau of Animal Affairs estimated that 500,000 pounds of dog faeces were hitting the streets every day. The city’s population was growing. More people meant more dogs, more dog excrement and less space to step around it. That affected not just dog walkers but everyone else using the streets.
This sounded analogous to the interweb’s superhighways. While some people are having fun, other people are stepping in the dog doo-doo we make. I read on.
The dog doo-doo battle of many armies
There was a long battle to clean up New York City, it lasted for most of the 1970s. The battle involved many familiar armies.
There were a mix of civil society groups in the battle. Some wanted cleaner streets, others just wanted to keep walking their dogs, and some saw the opportunity for self-publicity. There were also people who didn’t care about the battle being waged under their feet.
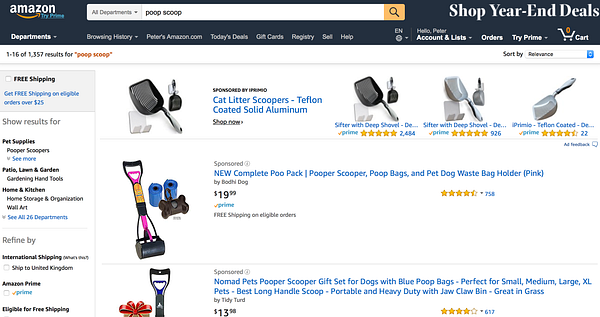
A search on Amazon shows 1,357 results for ‘poop scoop’
There were businesses in the battle too. Some businesses simply wanted cleaner streets outside their shops. A pet food association objected to the final legislation because of the impact it might have on their customers, dog owners. Other businesses saw new opportunities. There was a boom in innovative, and probably disruptive, dirt cleaning solutions that continues to this day.
Different government organisations took positions. In 1970 a new city Environmental Protection Agency had been created. Its leadership saw the opportunity to clear up a problem affecting citizens. Other organisations didn’t want the cost of enforcing new legislation and argued for others to take the lead.
Some organisations seemed to see a chance to pass part of the cost, and blame, for cleaning the streets to dog walkers. I suspect many other government organisations were wondering why all this effort was being spent on canine coprolites.
Meanwhile politicians were trying to navigate between all of these interest groups to tackle both this problem and others facing the city.
Politicians talking crap
Throughout the 1970s some argued that people could be persuaded to change behaviour without legislation through campaigns and leaflets. Both civil society groups and government organisations tried to do this and had some effect in parts of the city.
Others said dogs should use bathrooms in houses, use different sides of the street on alternate days, or even be banned from the streets altogether. The mess caused by dogs risked all the enjoyment being taken away.
Some dog walkers, government organisations and politicians said that it was government’s job to scoop the poop and that government should have more resources for street cleaning.
There were politicians who thought that no legislation was needed as other problems took a higher priority. One politician said that he was keen for the legislation to happen as it would encourage city staff to focus on dogs rather than car parking fines. All politicians were heavily lobbied, by dog lovers and dog poo haters.
I can see a common pattern here. Regardless of whether the policy is about data or doo-doo we need public debate to gather ideas and decide who has to do what, what resources they have to do it with, and whether they get paid for the doing.
There was a campaign over public health issues with statements that an illness called toxocariasis, which can be caused by worms in dog excrement, was causing loss of eyesight in children. This risk appears to have been significantly overstated, although it looks like incidents of toxocariasis are reducing in the UK since dog waste laws were introduced there, but it was an effective campaign.
The debate raged until Ed Koch became Mayor and took a different tack. Rather than having another go at getting a new law passed in New York City’s legislature, he took the problem to the politicians at the New York State Senate. At the state level politicians debated how different solutions are needed in cities to more rural areas and passed legislation that only affected large cities (***). The law gave the city the power to fine people who didn’t scoop their pooch’s poop.
In all policy work sometimes you have to explore a few paths before you get to your goal.
Clearing up dog shit is good for society
Throughout the debate there was a common thread. A city that welcomed dogs but that had less dog faeces scattered around would be a better city.
Dog owners enjoyed the company of their dogs, but other people in their local communities were affected by their enjoyment. Pavements, or sidewalks in NYC, are shared spaces. Use and misuse of that shared space affects everyone who lives in the city. After a debate dog owners were prepared to take on the task of clearing up some of their mess for the benefit of wider society.
A super pooper scooper sign in North Vancouver communicating the new social norm in multiple languages. Image via “New York’s poop scoop law: dogs, the dirt and due process” by Michael Brandow
It is hard to know what was most effective — the debate, the civil society campaigns, the leaflets and signs, government loudly declaring that it had legislated, or the final push of fines. I’ve struggled to find good crap data. But the repeated legislative battles show us that NYC policymakers thought a law was required.
The shift from the streets and dog walkers of my childhood to one where only 3% of British people will not pick up dog poo is a significant change for the better (****). That is social change in action. Social change that made my walk a bit easier. Even though I now had to clear up after my sister’s dog everyone, including me, could enjoy the park a little bit more.
But, does this tale teach us how to make data better?
A crap analogy
Well, not directly. The title of this blogpost wasn’t a joke. It is a crap analogy. Our motives for using data are different from the simple motives — have fun, feel safe- of walking a dog. Data is not like doggy doodah.
While data is not like doggy doodah, Misha Rabinovich has shown that you can use data about faeces to make art. This artwork is temporarily installed at the Open Data Institute for a 2018 exhibition. I wonder if it subliminally got me thinking about this blogpost.
We can all agree what dog poo is, but we cannot all agree on the mess being created by how people are collecting, sharing and using data. We haven’t reached an agreement on what ‘good’ looks like and what outcome we are trying to achieve.
Meanwhile although the data ecosystem contains many of the same actors — individuals, civil society groups, businesses, and government organisations — each with their own changing motives and power it is more than a physical city. There are multiple virtual global villages which manifest themselves in our physical towns, cities, nations and continents. Someone in the UK can create mess on a virtual street used by people in Uruguay, the Ukraine and Uganda. It is trickier to deliberately change social norms and create better outcomes in such a complex system.
But the tale should remind us that given time and effort people are willing to change behaviour and reduce the negative impacts they have on other people. Do you need a New Year’s resolution for 2018? Let’s keep having fun with data, but let’s think more about other people and clean up some of the shit that we’re creating.
(*) and other pets, such as cats, that also lead to interesting tales about data
(***) UK politicians and dog waste policymakers would possibly benefit from reading that 1978 New York State Senate debate as it seems that UK is still discovering that while bagging it and binning it works in cities, in more rural areas you need to stick it and flick it.
(****) despite the improvements some people want city streets that are completely clean of the odious dog ordure. You will regularly see news articles about towns and cities saying that they might use CCTV tracking, registration schemes, and dog DNA databases to catch offenders. A company called MrDogPoop claims to have “the most powerful Dog Poop DNA matching database in the world” to help track down poops that avoid the scoop. These city-wide schemes tend to disappear when people realise the cost and debate uncovers that a rover registration scheme is too much of a stretch to our social norms.
In my job at the Open Data Institute I sometimes talk with people, from businesses and governments, about how better use of data can help them design and deliver better services. I’ve been using a public sector example recently that I’ve not written down. Here it is.
Ways to get bus timetable data to people who need it
The example I use is bus timetables. People need to know the times and routes of buses so they can make a journey and get to their destination. When I use the example I talk through four of the patterns that can be seen in many cities and towns around the world for services that get bus timetable data to people who need it.
Mass market private sector services: many cities and towns now have bus timetables available as open data. Private sector services like Google Maps, Apple Maps and CityMapper pick up this data and build it into a service which they aim at the mass market of smartphone users. The services work in many cities and might haveother features such as information about restaurants and pubs. They get their open bus timetable data either directly or through a data aggregator, like TransportAPI or ITOWorld, who collate data from multiple cities / transport providers. That takes aways some of the effort from using open data and makes it easier for more people to build services.
Targeted private/public sector services: smart cities and towns recognise that the mass market services don’t always meet all needs, particularly accessibility. If you look closely you can often find small bits of public services meeting the needs of some users, or a transport authority running a challenge to help focus the private sector market on meeting particular user needs. Left to its own devices the private sector might only target the profitable and easy-to-serve mass market, a challenge can help change that to build more accessible services or to experiment with new technologies like AI or voice interfaces. Targeted services often use the same data aggregators as the mass market services. It’s the same data, just presented for a different set of user needs.
3. LocalBusTimes: a local website and/or smartphone app where people can look up the timetables for a journey they want to make. It might be for a whole town or a single bus company. It probably started by only providing bus timetable data, nowadays I think more of them recommend a route. The local authority or bus company typically run the LocalBusTimes service themselves.
4. Physical services: not everyone has or uses a smartphone when they need bus timetable data. There are many reasons for this. To give just a few: there might be no coverage, they might not be able to afford a smartphone, they might have run out of credit/data, they might not want a smartphone, their city might not have made bus timetable data available or they might simply have run out of battery. That’s why bus stations have information desks, why bus stops have timetables printed and stuck to them and why people ask other people “when’s the next bus?” on the street. Someone has used the bus timetable data as part of the design for the bus stop or as part of designing an operational process to help a human answer another human’s questions.
Some of the reactions I get to my example
No one, yet…, has told me that my example is stupid or dull. Feel free to be first to do that.
When I talk through this example with people the usual reaction is that while lots of people knew about the transport sector and data few people had thought of all the patterns or wondered about how they could be applied to their work in another sector.
Most people had used the mass market services but very few people had thought of using the market, in this case through open data and challenges, to help them meet their own goals. Those that had thought that they risked losing control to the market and hadn’t realised that they could still discover if user needs were being met — for example through user research — and could use a variety of ways to shape the market to target unmet needs. Challenges are just one of the ways to do that. Governments can legislate. Both businesses and governments can use procurement, strike deals, make different types of data more open, either fully open or in a more controlled way through APIs, or lots of other forms of soft power to shape the market around them.
I also find that few people had thought of the physical services pattern as part of the overall service. I find that sad. It also shows that I’m in a bit of a bubble and exposed to only some views. The tech world is overly focussed on services that end in smartphones and websites. I expect/hope that’s a passing phase.
Why I’m writing this down now
I’m writing this down now because I’ve been using the example for a while. It’s good to publish it to get my thinking straight, to show some of the reactions I get and to learn from new reactions. As I often say, data is becoming infrastructure that will be as open as possible. Businesses and governemnts need to adapt to that future. They have different goals, and needs for democratic accountability, but can learn from and collaborate with each other. I’m expecting to do some more work on public sector service delivery models over the next few months. It’s good to share, even shoddy, thinking early. It’ll help make that work better.
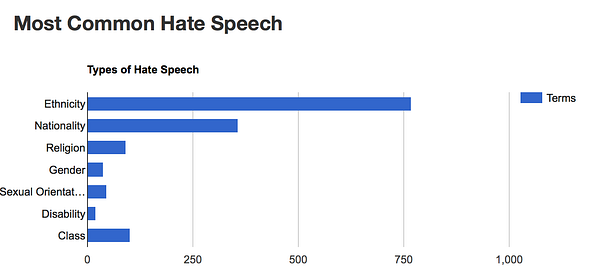
Warning: this post contains content that will be offensive to some people.
The post is a version of talk I gave at the ODIFridays series of lectures at the HQ of the Open Data Institute in London. The slides and a video of the talk are at the end of the post. Like most of my talks I adlibbed a bit. The post has links to most of the material I adlibbed from, others are at the end of the slides. It includes some thoughts on swearwords, Roger Mellie, democracy, censorship, Blackpool FC, artificial intelligence, context and an apology to my mum.
One of the UK’s regulators, Ofcom, commissioned research on offensive language last year. The research got lots of headlines. It was a nice opportunity for papers and websites to make cheap gags about swear words.
But it also gave me an opportunity to open up some swear word data and to use that example to talk with people and think about things like democracy, censorship, context and artificial intelligence. I made some cheap gags about swear words too.
After some discussion within the ODI and with Ofcom’s research team we ended up with this. The same data as the PDF but in a format that is both human and machine readable.
Now, a big part of our job at the Open Data Institute is “getting data to people who need it”. Normally I start with problems but this time I had started with data. My bad. Now to find out who needed it and how they would use it.
Some of the things people use this swear word data for
As I put the data out on twitter there was a background mantra of “arse…balls….knob…bastard…” from around the office. One person then wrote a little script that people could use to get their computers to say the list of words. Soon I could hear both human and machine voices swearing away. The swearing mantra was charming, if a little unsettling, but I had my serious face on. Why do people swear?
The main purpose of swearing is to express emotions, especially anger and frustration.
Seems fair. I suspect that a lot of people get frustrated at not being able to get data they need to do something. That explained the background mantra from the Open Data Institute office, but what about other uses of the data?
Roger Mellie, copyright Viz. Note that the swear word data might allow people to block his language, but not his gestures.
The content of the report told us about some other users. It would help TV broadcasters and presenters understand how people would react to things that they said on air and so help the presenters decide what they could say.
For example the word “bollocks” was seen as somewhat vulgar if it referred to testicles but less problematic if it was being used to call something ‘nonsense’.
This might mean that people did or did not say words in certain contexts. It might lead to some content only being accessible if a PIN was entered to unlock it.
We have given Ofcom the power to fine organisations and people that breach their codes. By publishing the report openly, they were helping broadcasters understand how they might use those powers and therefore discouraging breaches. This probably makes the system cheaper and more effective.
Broadcasters are likely to have their own guidance to help them meet the expectations of their target audiences. They could merge Ofcom’s list with their own list to help them meet both society’s needs and their own user’s needs.
Similar data is maintained in contexts outside of TV and radio
In Britain Mary Whitehouse was a famous campaigner from the 1960s to the 1980s against things that she found offensive. I can imagine Mary being keen on data-driven censorship. Image fair use via Wikipedia.
The data includes the word ginger saying it is ‘mild language, generally of little concern’, but the word ginger can also be used to describe a very tasty type of biscuit. A filter that used the swear word data to block offensive words might ban ginger nuts. That would be bad. This is a common problem with simple data-driven solutions. They ignore context.
I couldn’t find a list of offensive biscuit names but there are other sets that are similar to the swear word data used in contexts other than TV and radio.
The UK has a list of suppressed car registration plates
It is the job of part of the UK government, the DVLA, to maintain a list of combinations of letters and numbers that you cannot put on a car. Unfortunately, and curiously, the list is not published openly, but sometimes it is made available after freedom of information requests.
An extract from the suppressed car registration plate list via Whatdotheyknow
The list of suppressed car registration plates helps prevent confusion over typographically similar symbols, like o (zero) and 0 (oh). It blocks language that is likely to be considered offensive, for example “*B** UMS” and “*R**APE**”.
The list also explicitly contains the names of terrorist groups such as the UVF, UDA and UFF. Another terrorist organisation, the IRA, are already banned, like any other organisation beginning with I, because of the potential for confusion between 1 (one) and I (aye).
More controversially the acronym for the far-right British National Party, BNP, is also on the list. The BNP are allowed to stand in the UK’s democratic election process. How was that decision made? Unfortunately just as the list isn’t publicly available neither is the methodology.
Context affects what words are offensive
The UK’s democratic processes produce others lists of offensive words.
The speaker in the UK’s parliament can request that politicians withdraw words when debating with their opponents, so called unparliamentary language. The way in which words are deemed to be unparliamentary or not are unclear. In 2015 the opposition leader Ed Milliband was allowed to call the then Prime Minister David Cameron “dodgy”, yet in 2016 an opposition backbencher Dennis Skinner was asked to leave a debate because he called David Cameron “dodgy Dave”. The word “dodgy” isn’t on Ofcom’s list, it’s offensive to call an MP “dodgy” in a parliamentary debate but not to call them it on television.
The word “Oyston” is offensive to me and my community of fans of Blackpool football club. The offensiveness is not only because of this cringeworthy picture but because of how the Oyston family treats fans.
Another example of offensive language in a particular context is the word “Oyston”.
The Oyston family own the football club that I support, Blackpool FC. Because of their actions against fans being called an Oyston fan on one of the websites used by Blackpool fans would be offensive. How would anyone outside of the community of Blackpool fans discover this?
There are related examples that may help us understand how we could do this.
Collaborative maintenance of data
Hatebase maintains a list of hate speech from around the world. The data is maintained by automated processes and manual interaction to cater for how hate speech changes over time and in different places. Hate speech can be used to encourage violence against people and communities. The collaborative maintenance process allows people to debate which words are hate speech or not.
Other people could learn from the example of Hatebase. If British politicians wanted, and could get to grips with github, then they could collaboratively maintain my initial list of unparliamentary language and create something that would help them understand the boundaries of offensiveness.
Offensiveness is affected by time, place and communities
By this point in my own research I was clear that the context of offensiveness is affected by time, place and communities.
When I checked I found that swearing philosophers were, of course, already aware of this. As often happens I was a technologist rediscovering ground that others had already covered. But technology can also affect how and which words become offensive.
People create new offensive words
Oyston is an example of a word that became offensive to a small group of people before becoming offensive to a larger group. Blackpool fans have effectively used social media and the press — oh, and talks & blogposts like this ;) — as part of a campaign to get the Oyston family out of our football club. An effect of this has been to spread the understanding of the offensiveness of the Oystons from the seaside to wider parts of the footballing community. A more famous example is the case of Rick Santorum who found his surname defined as an offensive word in a campaign led by Dan Savage.
This is a challenge to any list of swear words and a risk for people who use them. People create new offensive words for their own purposes. They game systems.
Would people game the swear word data I created from Ofcom’s list? Yes, of course they would.
An example quickly came to mind. When I published the Ofcom offensive word list as open data then in line with good practice I gave every entry a universally unique identifier (UUID). UUIDs make it easier for machines to use the data.
If this data was to get widely used then how long would it be before people started to circumvent the system by being interviewed on telly wearing t-shirts with the UUID of a swear word? Perhaps over time the UUIDs, or parts of them, would become offensive? “That fella’s a right 81cb.“, they’d say. Maybe the UUIDs would need to be added to the list as they became offensive?
People adapt and change. That is one of the best things about people and one of the biggest challenges we face when maintaining and using data. We need to build in mechanisms to change datasets over time as needs and uses change.
Swear words-as-a-service is hard
It is clear that swear word data was easy to build and also clear that it would be more difficult to maintain and make it useful in multiple contexts.
I knew that many companies were already maintaining similar lists as, like many other people, I had seen, laughed and evaded filters on websites that had turned the British town of Scunthorpe into the apparently inoffensive “S***horpe” due to simplistic and bad data-driven algorithms. I do wonder how useful those filters and services are.
Many of the website filters I had seen are simple and flawed because of the lack of context and their inability to adapt to people’s changing behaviour but thinking ahead I wondered if people would start to apply machine learning / artificial intelligence (ML/AI) and create services that could automatically learn new swear words? Perhaps this could be used on a massive scale to reduce the damage caused by offensive language on the web?
I knew that I wouldn’t be the first person to think of this idea. While 2016 had been the year when every problem could be fixed with a blockchain, 2017 is the year of ML/AI.
A quick search of patent libraries showed that in 2015 Google had registered a patent to classify offensive words using machine learning. Unfortunately it looks rubbish. The training mechanism worked on a large set of text samples, it failed to recognise the context in which the text was being used. The resulting service might be slightly better than current filters but would still be data-driven rather than informed by data.
Maybe, like Hatebase, it would help if users were to train the machines that provided the service. After all Google, like most other large internet companies, use thousands of people — including you — to help train their services. I started to consider what I had learn about offensive language and think of the tasks that Google would need to give to swear word raters to train their machine:
Task: go to a football ground in Gdansk, Poland. Play this video to people near you. Observe their attitude to you, and each other, over the following seven days and then categorise the offensiveness of the video. Repeat this exercise every 3 months.
Hmm… I quickly realised that this might be a Quixotic mission and that AI/ML might provide a better service but still only a partial one. There would be no perfect service. People decide what is offensive, not machines. If the service only considered some contexts then the people who controlled the machines and trained them on those contexts would be the ones who decided where it was useful. Swear word data isn’t like the location of bus stops or the list of transactions in a bank account. The context is even more important.
This is one of the challenges of the web and providing data and services for it. The web is pervasive. It interacts with the physical world in many places. It appears in multiple contexts. I use the web to watch broadcast news, like that regulated by Ofcom. I use it keep up to date on politics, where the unparliamentary rules are useful. I talk about football, and the Oystons, on message boards. I keep up to date on current affairs, and feel helpless at the levels of hate speech deployed at people in the UK and abroad. I chat to friends, both publicly on sites like Twitter and Facebook and also privately in messaging applications.
Datasets and services that reduce offensive content on the web will need to cater for all of these different contexts, and more. Even if they do, some people will still work around them. Data and technology may be able to help the problem but it will only ever be part of a solution to something that is fundamentally a more human problem. Our need to express our emotions in language.
Sorry mum
It was clear from my investigations that we could usefully create data about swear words, i.e. words that are offensive. That the need for this data came from people who swear, people who didn’t want to swear and societies & communities trying to decide the boundaries between what was offensive or not. That it would be useful if the research and rules for deciding on what was offensive were open. And that if people could collaborate to decide on what was offensive that the data would be more useful because it would cater for more contexts. But it was also clear that while technology creates new possibilities to reduce offensiveness that people will still adapt to achieve the goal they want. So it goes.
The other thing that was clear from the talk was mine and my audience’s squeamishness with some of the words. In my case it was certainly because of one of my most important contexts: my upbringing and my family. I’d like to end this post the same way I ended the talk by apologising to my mum. Sorry mum.
The questions from the audience showed the importance of context
At the end of the talk at the ODI the audience raised several points about offensive language that had not been covered in the talk, such as the use of racial and religious slurs. I was already covering a wide topic. Racial and religious offensiveness cover even more ground. I couldn’t cover everything.
Image from The Wanderers, based on a book by Richard Price. The film includes a fantastic scene in a 1960s New York school where people of different religions and ethnicity try, and fail, to remember all of the offensive names they have for each other.
I did find it interesting that the audience in the room hadn’t heard of some of the words in the list. Particularly choc ice, blood claat and bum claat, words that in my — white, middle class, mostly Northern England and South London experience — are used against black people or in black communities. In the case of the latter two more specifically within Jamaican communities.
That people hadn’t heard of these words says something about the context of the audience. A context where those words may not have been seen as offensive. Perhaps next time I talk on this topic I should try and sneak in some offensive language from different contexts to see what happens.
Watch the original talk or read the slides
If you want you can watch a recording of the talk (which includes some swear-a-long fun):
Phillip discussed various policy options to tackle the challenges. The options includes banning ground rents or limiting how much they could increase in value and many other subtle tweaks.
Hello, thank you for inviting me. I’m from the Open Data Institute (ODI). You may not have heard of us. (murmers of agreement)
We were founded 4 years ago by Sir Tim Berners-Lee, the inventor the web, and Sir Nigel Shadbolt. Our CEO is Jeni Tennison, she apologises for not being here. So do I as I’ve ended up creating an all-male panel. That’s bad.
We are global. We connect, enable and inspire people to innovate with data. Or “to get stuff done that make things better by being more open” as I sometimes say.
I am not a housing or leasehold specialist, my job is to get data to people who need it. Leasehold Knowledge Partnership are part of our current UK startup programme. They’ve been helping us understand the problems in leasing, we’ve been helping them understand whether more data can help.
Freeholds sold without leaseholders knowing ("who owns my house?"), others trapped with ever-escalating ground rents
When data is open and available for anyone to use it is easier for people to use it to make decisions and solve problems.
Take leaseholds. Let’s imagine if more information was open while respecting the privacy of homeowners.
People expect easy access to data in the web age. Many homebuyers use sites like RightMove and Zoopla as they look for a home. Opening up leasehold data would enable those services to help people make an informed decision. For example they could compare terms with other properties, leasehold or not, in the area and see what’s reasonable. Some of the cases Patrick mentioned happened because people lacked information when buying a home.
Phillip Rainey QC asks whether leaseholds are a means to an end (buying a flat) or are we inventing an asset class?
Conveyancers and estate agents would have access to more data too. They could get things done faster and give better advice to homebuyers.
Researchers would be able to model the market; help people understand how it is working and suggest improvements
Legislators would be able to get better information about problems, where legislation is needed or where soft power could be used to influence things
With better access to data government could test a policy idea, like the ones Phillip suggested, in a region before deciding whether to roll it out nationally
"If we can define the moon in legislation we can define ground rents and how they can be used"
Much of this data is available but it is locked away. In government offices, in the offices of house building firms, in law firms or in contracts held by leaseholders and freeholders.
Some of our big public registries and institutions – things like the Land Registry, Ordnance Survey, the Met Office — were created to make this type of information available to people who need it but it feels like they haven’t adapted to changing times and 21st century needs.
Getting this data open can take time and cost money. Not that much, technology can be cheaper than some people might tell you. But getting the data open and using it to change markets, like leasehold, can also affect business models. That’s usually more significant.
Phillip Rainey QC "Are we at risk of ossifying the housing market with new property on 999-year leases"
In closing I’d ask both the members of the APPG and all of the leasehold experts in the room to think about the power of the web, what people expect in the modern age and how the tools and techniques of the web and data can help build a better housing market. One that can reduce the number of cases like those that Patrick Collinson has written about over the last few months.
After the various speeches questions were asked by people in the room. The questions were from a more diverse group of people than the the all-male panel (grr!).
I was asked whether there was enough data available for someone in Ellesmere Port to get a reasonable view on whether their leasehold flat will be worthless in 10 years time. I’m checking that today.
Someone else raised the issue of freehold management companies surprising people with unnecessary administration fees — for example £250 for a simple bit of paperwork that is necessary if the homeowner wants to sell their home. That’s an issue my wife and I are well aware of having just sold our leasehold flat in London. We plan to blog on how data helped and where some data was missing.
Someone else asked whether we knew if the problem with leaseholds was bigger than in the 1970s. The answer from the panel was a bit vague but Phillip Rainey raised an important point. He said that the problem was getting worse because lawyers were producing new tighter leasehold clauses that benefitted the freeholder. He said that lawyers used the web to share these new clauses so they were all getting better in a way that made the situation worse for leaseholders.
You see technology can be used for good and bad and — as a very wise person once said — knowledge is power.
To help level out power imbalances we need to share the knowledge and the skills to use it with everyone.
These are the approximate words I said at the launch of the new All-Party Parliamentary Group (APPG) on data analytics on 31 October. An APPG brings together representatives from different political parties from both the House of Commons and House of Lords to pursue a particular topic or interest. Daniel Zeichner MP’s speech from the launch is also online. Other speakers were from TfL, Experian, CompareTheMarket and the Institute for Environmental Analytics. In person I wandered off topic a bit based on audience reactions but I promise that there were no cat jokes.
It is based in London but the network is global. We have nodes and members on six continents and in every nation of the UK. We do research, train people, advise them, introduce them to people with similar interests, give them simple tools to help them publish and use data, incubate startups and encourage thinking on fundamental issues such as data infrastructure and how to use personal data in a way that creates trust. We do this with large businesses, startups, charities and governments. We are a global voice for the better use of data to deliver social, environmental and economic impact.
The ODI is a not-for-profit and was founded five years ago by Tim Berners-Lee and Nigel Shadbolt. Both of them are at the yearly ODI summit which takes place at the British Film Institute tomorrow.
Bringing people together to solve common problems
The ODI team at the 2015 summit. Don’t let anyone convince you that diversity in tech is impossible, it’s not. Image by Paul Clarke, CC-BY-SA.
The summit is kind of unique, as is the ODI. It brings together large corporates with charities and startups; people interested in global development and democracy with people interested in the latest smart cities and transport trends; people from local government, national government and reps from global institutions. The attendees and speakers come from around the world. They all believe that openness and data can benefit them and everyone else too. (you can watch a stream of many of the summit sessions)
Which brings me to this all-party parliamentary group on data analytics. I’m a big fan of democracy and I’m also a big fan of things that bring together people from different backgrounds such as elected representatives and peers from across the political spectrum to find common points of interest, or problems, where people can work together to get things done and make things better. It’s the type of approach we use to help bring together large sectors like banking and agriculture, another one will be announced tomorrow. I won’t spoil the surprise. (it was sports)
An age of data abundance
We are in an age of data abundance with billions more people and devices coming online. It’s ever cheaper to collect, use and publish data. A web of data is evolving that sits alongside and behind the web of documents which changed our lives when Tim Berners-Lee invented the web 20-odd years ago. Our experience from the last 5 years is that that data will create most value when it is as open as possible while respecting privacy: an open future. But the future is uncertain.
We need to work together to shape an open future because whilst the current wave of technology change has bought many benefits it also carries many risks. Privacy risks, monopoly risks, democratic risks. We need to overcome those risks and project a positive message to get to a good future.
Tim famously said “this is for everyone” when tweeting about the world wide web from the launch of the London Olympics in 2012. The type of open thinking that Tim showed when he gave away the web is going to be necessary if we are going to realise the brilliant potential of this new web of data to benefit everyone.
And that open thinking is what we hope to see from this all-party parliamentary group. As well as the rest of us we need government and legislators to play an active part in making this happen. Government can lead by example.
We need to provide data skills for citizens, business and policymakers, with policymakers using data both for evidence and as a tool to achieve their policy ends.
And we need to encourage open innovation. A bridge between academic research, public, private and third sectors, and a thriving startup ecosystem where new ideas and approaches can grow. Innovation that solves problems.
We describe this as the open future. A future where we’ve understood and tackled those risks, made data as open as possible and created benefits for citizens, businesses and government. Data for everyone.
There were questions
After we talked the audience asked questions covering a whole range of topics from data in manufacturing and engineering; trust in use of data; public sector reform; EU proposals for copyright and how that impacted on organisations holding data; and whether people should be paid when their data is used. A wide range, as you’d expect from something that connects together and underpins sectors across the economy.
The last two questions I found particularly interesting. Both of them seemed to come from applying models from the real world to something, data, which has different qualities. Data is non-rivalrous, it benefits from network effects, etcetera. That’s why the economics of data are different from other things and still being researched. The questions also seemed to come from an implicit assumption that we could use the concept of ownership in the physical sense of the word. We need to be careful in how we use the language of ownership to address questions about data. Physical world metaphors don’t readily fit the data world. And even our understandings and expectations of ownership in the physical world aren’t as simple as they seem. This blog from Ellen Broad is a good read and what I channeled in my response. I hope the APPG thinks about those questions and the concept of ‘data ownership’ deeply. Its members will be part of shaping the legislative environment that will help us get to that open future.
Hello. This is the personal website of Peter K Wells. I do politics, policy and delivery to try to make data and technology benefit everyone. I also do bad jokes and music references.
This website stores cookies on your computer. These cookies are used to provide a more personalized experience and to track your whereabouts around our website in compliance with the European General Data Protection Regulation. If you decide to to opt-out of any future tracking, a cookie will be setup in your browser to remember this choice for one year.