Approximate words from a talk at the Holyrood Connect: Data Forum in September 2016. Approximate as I tend to ad-lib in person as I see shocked, or occasionally, pleased faces in front of me. I also had a bad cold so ad-libbed even more than normal. The slides are also available online.
— — — –
Hi, I’m Peter. I do some stuff at the Open Data Institute (ODI). I’m here to talk about how an open city is a better city.
First some background and a couple of concepts: the data spectrum and data infrastructure. Then some current examples of data analytics in cities, and their limitations, followed by some UK examples of people building more open cities with more benefits. I’ll end up with some principles to help get you started and a bit about what’s coming in the future. Ok, background:

Background
The ODI was founded four years ago by people like Tim Berners-Lee and Nigel Shadbolt. It is headquartered in the UK but its team works around the world. There are currently 29 nodes in 18 countries. In the UK that includes places like Aberdeen, Leeds, Belfast, Devon, Bristol and Cardiff.
The ODI’s mission is to connect, equip and inspire people around the world to innovate with data. We believe in knowledge for everyone. We help the public sector, third sector, academia and businesses to get more impact from data. Last week there were research fellows in the office from Madrid and Singapore debating and sharing ideas about geospatial data and privacy, crowdsourcing and smart cities. In the last few weeks the HQ team have been doing stuff in the UK, in Malaysia, New York, Mexico and Tanzania.
Concepts
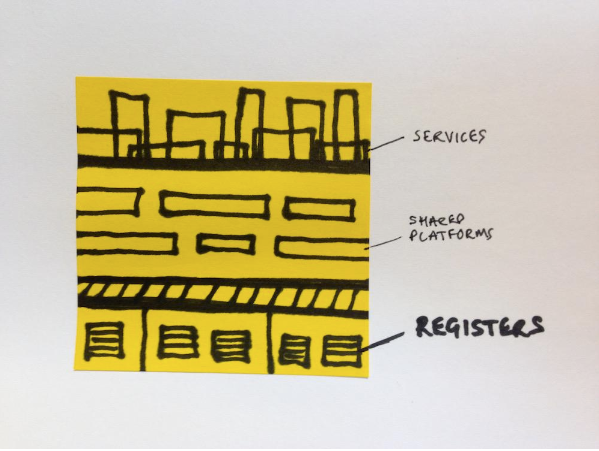
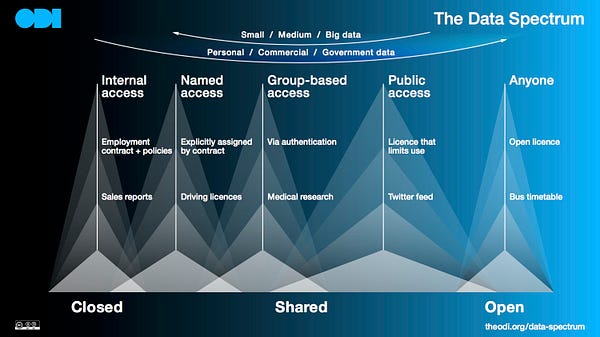
The ODI works across the data spectrum. Some of us worry about personal health records being “made open”. Some confuse commercial and personal data, or mix up “big data” with “open data”. To unpack data’s challenges and its benefits, we need to be precise about what these things mean. They should be clear and familiar to everyone, so we can all have informed conversations about how we use them, how they affect us and how we plan for the future. And it doesn’t have to be complicated. It can be simple. In one image. Whether big, medium or small, whether state, commercial or personal, the important thing about data is how it is licensed and who can use it. Closed so that it can only be used within one organisation, shared can only be used by some organisations (because of rules or price restrictions), or open data that can be used by anyone for any purpose.

The ODI works to improve data infrastructure. Data has become vital infrastructure over the last few years. It underpins transparency, accountability, public services, business innovation and civil society. Data such as statistics, maps and real-time sensor readings help us to make decisions, build services and gain insight. Data infrastructure will only become more vital as our populations grow and our economies and societies become ever more reliant on getting value from data.
I often hear people say that data is the new fuel or that it’s oil for the digital revolution. Daft analogies. Data doesn’t get burnt up when we use it, we can use it again and again and again. It doesn’t get extracted from the ground: unless it’s geological data. The analogy we use for data infrastructure is roads. Roads help us navigate to a location. Data helps us make a decision. Roads have signs and maps to tell us how to use them. So does data, well hopefully.
Lots of cities are improving data infrastructure
Now back to the theme of cities and data. Cities and local authorities around the world are using and improving data infrastructure. It may not feel like it sometimes, but they are.
Many public sector organisations are developing skills and creating more impact by using their own data to make better decisions. Whether it be where to spend money on social care, what time to pick up the bins or how to design a local authority website so that it’s easy to use. In each case the organisation is having to learn how to gather data, analyse it and use it to make a better decision.
These are all activities in the closed part of the data spectrum.

We’re also seeing more and more public sector organisations work together and share data to make better decisions. Down in Manchester local authorities are sharing data to help vulnerable children. In London local authorities are sharing and analysing data to look for unlicensed houses of multiple occupancy, they can be unsafe places to live. This type of big data analytics takes inspiration from places like Chicago which has been using data about graffiti tags to tackle gang violence, or New York City and Amsterdam which have analysed data from across the city to work out what characteristics were the best indicators for fire and help prevent it.
These activities take place in the closed and shared part of the data spectrum.
All the data and all the open
But let’s go back a bit. When I talked about data infrastructure I said it underpins transparency, accountability, public services, business innovation and civil society.
All of the previous examples are about public services. The rest of the benefits of data infrastructure missing. There’s some business innovation — for example from data analytics companies selling into the public sector — but only a portion.
Why is that ? Let’s look again at the full data spectrum. We’re missing public data and open data.
At the ODI we say that cities, their businesses and their citizens get most impact from a data infrastructure that is as open as possible while respecting privacy. There’s lots of research showing this and there’s also practical examples. I’ll cover some in a bit.

The reasons that open data infrastructure creates most impact is due to the qualities of data. For example, it benefits from network effects. Data becomes more useful and creates more value as more people use and maintain it.
When you work openly and use as much open data as possible then more people can work together to solve problems, make decisions, find insights and build services. You benefit from network effects. You can build a better city. One that benefits everyone.
This is particularly true if you combine all the data — closed, shared and open — with all the open. Open culture. Open source. Open government. Open standards. Open innovation. Etcetera.
There’s lots of examples, here are some
Let’s take a few examples showing some different aspects.
First, Bath and Strava, the cycling app. Strava users cycling around Bath can choose to share their closed personal data with a community group called Bath:Hacked. That group preserve privacy, analyse the data and are working with the council to use it to improve cycling routes. Interestingly there’s anecdotal evidence that people are cycling and using the app more because they can see that the data they collect benefits the city and themselves. Win win. Meanwhile Bath:Hacked are sharing what they’re doing online.
There are two reasons for that. First, by opening up the knowledge for everyone other people can use it and other people can tell Bath how they are using it. People can learn with each other. Second, openness about how organisations secure and manage personal data builds trust. It can improve quality too. take Defra who recently did a privacy impact assessment in the open, with people outside the organisation commenting, before releasing diaries showing the diet habits of 150,000 households. They worked out by debating with their community that some of this data which would otherwise have all been kept closed could be made open for anyone to use. Transparency and open debate about personal data can make things better.
Another example, I was talking to someone from Devon council last week. They published a map of places where people could get help. Unfortunately the map was wrong. Because both the data and the source code were open a friendly person could fix it for them and send them the corrected version. Problem fixed within a few hours. Thank you friendly person.

Another. In places like Manchester and Leeds people from the public sector, private sector and civil society are working to build a low-cost open infrastructure for the internet of things. They’re helping each other using each other’s skills and experience as needed. On the infrastructure people will be able to build and deploy sensors to monitor air quality or the height of a river and anyone will be able to use the data to decide whether to place a new school near a road or a set of new houses by a river, whether to buy a house or whether to evacuate a house as the waters are rising…
These things cost money but they don’t need to cost the big money that so many projects with technology do. The cost of software, hardware and hence data is falling dramatically. You can now build an air quality sensor for less than £100, you can get a LIDAR sensor — a device that can measure distance using lasers — that used to cost tens of thousands of pounds for a few hundred pounds. (That’s part of the reason we’re hearing about automated cars so much. They need those sensors too). As much as possible of the data from that infrastructure will be open, that’s the culture of the community. That will allow other people to use it too for only the cost of allowing people to use the data that has already been collected. The infrastructure is designed for open.
And to continue the theme of culture. In Aberdeen the team in the council run hackathons open to anyone and learn innovative techniques from civil society businesses to help the council deliver other services. Those hackathons will also help with the Scottish government’s digital skills initiative that I was reading about on the train yesterday. An initiative that could also be supported by the new work that the Open Government Partnership are starting with the Scottish government.
Back to Leeds. The city council has funded ODI Leeds to act as a neutral space outside the council that can be used to convene businesses, academia, civil society and the public sector to understand and define problems; share data to explore ideas and then open the data as much as possible to allow people to build solutions. Those solutions could be built by new startups or established businesses. Arup, the global construction firm, use similar open innovation techniques working with startups to help improve how they build stuff. It’s like the data analytics examples we saw earlier but it uses the full spectrum.

In each of these cases we can see people from multiple sectors sector working together to solve common problems as openly as possible. In the process new businesses are built, there’s transparency and accountability, civil society are engaged, and there’s better public services too. All of the things our data infrastructure supports.
There’s countless more examples across the world for those who look.
How do I build open data infrastructure?
But, I often hear people ask, how do I do this?
As you may have realised from these examples data infrastructure is not only about data. Data infrastructure includes datasets; the technology, training and processes that makes them useable; policies and regulation such as those for data sharing and protection; and the organisations and people that collect, maintain and use data. We can all see that the datasets may be from anywhere in the data spectrum. But the more open the data infrastructure, the more value it will create as more people can use it.

Based on the ODI’s own work and research on what works and what doesn’t at city, national and globally we’ve published some principles to help other people build better data infrastructure.
The first and last principles are key. Design for open and encourage open innovation.
Based on our experience we believe we need a number of things to work together to create the space for open innovation to happen: strategy, policy, training, technology, research, a tech community, and engagement. With that engagement you’re looking to build a receptive internal customer (for example a councillor in a city), a responsive tech community and an engaged civic community willing to work with you. With open innovation the best answers can come from anywhere. You just need to get started and have the courage to try.
Anyway, I hope that was interesting, and useful, but before I go I want to leave with you another thought as to why getting to grips with open and data is so important.
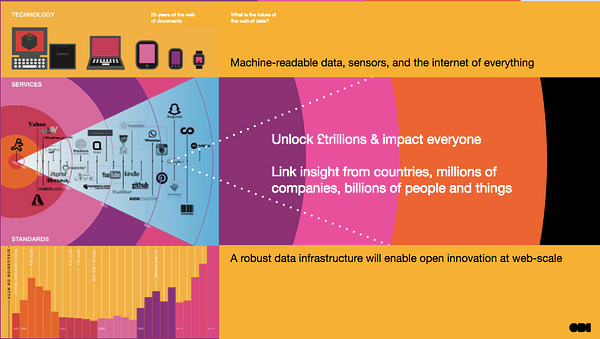
The web of data is coming.

Over the last 25 years we’ve all been building the web of documents. Billions of webpages linked together. It’s fabulous. But the billions of people, sensors and services that are connected to the web and the internet produce, publish and use data. A web of data is now evolving that sits alongside and behind the web of documents.
That might seem like a challenging thing and something we can’t control but I would encourage everyone to see it as an opportunity. By getting to grips with your data infrastructure and making it as open as possible you will be positioning your city and the businesses and citizens that live in it to thrive in that future. That sounds like a pretty important mission to be cracking on with. It’s about building for the open future.
An open city is a better city.
There’s countless other examples to demonstrate why an open city is better and to help you understand how to grow your city in a way that works for your problems and your challenges. But, as a start, I’d encourage all of you to pick a problem and get started. Work together with your businesses and citizens to solve that problem and start building that open city and make things better for everyone.